Contents
- Utilisation d’AWS Backup pour créer des sauvegardes
- AWS Backup et son interaction avec d’autres services basés sur AWS
- Opérations de base avec la console Amazon S3
- Autres méthodes de sauvegarde de votre bucket Amazon S3
- Solutions de sauvegarde AWS S3 de qualité professionnelle avec des coûts de restauration minimes.
- Sauvegarde AWS S3 avec Bacula Enterprise
- Ajout d’un nouveau stockage S3 dans Bacula Enterprise
- Configuration de votre sauvegarde du stockage AWS S3 avec Bacula Enterprise
- Terminer le processus de configuration du stockage S3
- Sauvegarde de vos nouveaux paramètres de sauvegarde S3
- Test des paramètres de sauvegarde AWS
- Conclusion
Utilisation d’AWS Backup pour créer des sauvegardes
La sauvegarde de vos informations (données) est peut-être l’élément le plus important pour les protéger de tout dommage et assurer que vous soyez en conformité. Même les serveurs et les systèmes de stockage les plus durables sont susceptibles d’être victimes de bugs, d’erreurs humaines et d’autres causes possibles de sinistre. Mais la création et la gestion de tous vos flux de travail de sauvegarde peuvent s’avérer une tâche décourageante dans l’ensemble. Par conséquent, il existe une variété de méthodes que vous pouvez utiliser pour simplifier l’ensemble du processus de création d’une sauvegarde tout en utilisant AWS S3.
Un choix populaire est la propre solution de sauvegarde d’Amazon – AWS Backup. La sauvegarde AWS peut fournir un moyen de gérer vos sauvegardes à la fois dans le nuage AWS et sur place, ainsi que de prendre en charge une variété d’autres applications Amazon.
Le processus de sauvegarde en lui-même est assez simple. Un utilisateur doit créer une politique de sauvegarde – son plan de sauvegarde – en spécifiant un certain nombre de paramètres tels que la fréquence des sauvegardes, la durée de conservation de ces sauvegardes, etc. Dès que la politique est mise en place, AWS Backup devrait commencer à sauvegarder vos données automatiquement. Ensuite, vous pourrez utiliser la console d’AWS Backup pour visualiser vos ressources sauvegardées, avoir la possibilité de restaurer une sauvegarde spécifique ou simplement surveiller votre activité de sauvegarde et de restauration.
AWS Backup et son interaction avec d’autres services basés sur AWS
Il existe de nombreux services AWS différents qui peuvent offrir diverses fonctionnalités utiles et fonctionner en tandem avec le service AWS Backup. Par exemple, ces services comprennent, sans s’y limiter, les services suivants
- Amazon EBS (Elastic block store);
- Amazon RDS (Relational database service);
- Amazon DynamoDB backups;
- AWS storage gateway snapshots, etc.
Bien entendu, vous devez activer le service spécifique que vous souhaitez utiliser dans votre processus de sauvegarde avant de l’utiliser en premier lieu. Si vous essayez de lancer ou de créer la sauvegarde en utilisant des ressources spécifiques d’un service que vous n’avez pas encore activé, vous recevrez probablement un message d’erreur et ne pourrez pas effectuer le processus de création.
Pour trouver la liste des services que vous pouvez activer ou désactiver, vous devez suivre un certain nombre d’étapes :
- Ouvrez la console de sauvegarde AWS.
- Allez dans le menu « Paramètres ».
- Allez à la page « Service opt-in » et cliquez sur « Configurer les ressources ».
Cela devrait vous amener à la page contenant un certain nombre de noms de services et de boutons à bascule, et vous pouvez facilement activer ou désactiver chacun des services spécifiques. En cliquant sur « Confirmer » après avoir effectué les changements, vous sauvegarderez vos opérations.
La sauvegarde AWS est capable de mettre en œuvre un grand nombre de capacités de services AWS existants dans le processus de création d’une sauvegarde. Un bon exemple de cela est la capacité de snapshot EBS qui est utilisée pour créer des sauvegardes selon le plan de sauvegarde que vous avez créé. La création de snapshots EBS, quant à elle, peut être effectuée à l’aide de l’API EC2 (Elastic compute cloud). Ainsi, vous pourrez gérer vos sauvegardes à partir d’une console de sauvegarde AWS centralisée, les surveiller, programmer différentes opérations, etc.
La sauvegarde AWS peut effectuer des tâches de sauvegarde sur des instances EC2 entières, ce qui vous permet d’avoir moins besoin d’interagir avec la couche de stockage elle-même. Le fonctionnement est également assez simple : AWS backup prend un instantané du volume de stockage EBS racine, ainsi que des volumes associés et des configurations de lancement. Toutes les données sont stockées dans le format d’image spécifique appelé volume-backed AMI (Amazon machine image).
Les fichiers de sauvegarde EC2 AMI peuvent également être chiffrés au cours du processus de sauvegarde, de la même manière que la sauvegarde AWS le fait pour les instantanés EBS. Vous pouvez soit utiliser la clé KMS par défaut si vous n’en avez pas, soit utiliser votre propre clé pour l’appliquer à la sauvegarde.
Le processus de restauration des ressources EC2 peut être effectué de plusieurs manières différentes : La console de sauvegarde AWS, la ligne de commande ou simplement l’API. Par rapport aux deux autres, la console de sauvegarde a beaucoup de limites de fonctionnalité pour le processus de restauration et ne peut pas restaurer plusieurs paramètres comme les adresses ipv6, certains ID spécifiques, etc. Les deux autres méthodes, en revanche, sont capables d’effectuer une restauration complète d’une manière ou d’une autre.
Opérations de base avec la console Amazon S3
La boîte à outils S3 d’Amazon permet d’effectuer certaines opérations de base lorsqu’il s’agit de récupérer ou de stocker un fichier spécifique à partir du bucket. Il est possible d’indiquer quatre opérations différentes qui peuvent être effectuées en utilisant uniquement le logiciel de sauvegarde Amazon S3 – mais nous devons d’abord accéder à la console Amazon S3.
Pour ce faire, il suffit de se rendre sur la page des services AWS en utilisant ce lien. En saisissant vos informations de connexion, vous devriez pouvoir accéder au premier écran de la boîte à outils des services AWS. Ensuite, il est possible de trouver la console S3 soit en allant dans le menu « Services » et en y trouvant S3, soit en tapant « S3 » dans la barre de recherche située dans la partie supérieure de la page.
- Créer un Bucket S3.
- Un bucket est un type de conteneur qu’Amazon S3 utilise pour stocker vos fichiers. Un bucket peut être créé dans l’interface AWS S3 en cliquant sur le bouton « Create Bucket » dans l’écran de titre.
- Il convient de noter que la page Web se présente différemment selon que vous avez déjà créé un godet auparavant dans ce compte ou non. S’il y a d’autres baquets déjà en place, vous verrez apparaître un écran qui vous permettra de gérer ces buckets, y compris de les renommer ou de les supprimer purement et simplement.
- D’autre part, si c’est la première fois que vous créez un compartiment dans ce compte de sauvegarde AWS S3, vous verrez un écran correspondant décrivant la manière de créer un compartiment en premier lieu. Dans ce cas, vous pouvez utiliser le bouton « Create bucket » ou le bouton « Get started », qui devraient tous deux vous conduire au même endroit – l’écran de création de baquet.
- La première invite de l’écran devrait concerner la création d’un nom pour votre nouveau bucket, et le champ devrait également vous avertir si le nom du bucket ne répond pas à certaines des règles d’Amazon relatives aux noms de buckets. Vous devrez également choisir une région appropriée pour votre futur seau. Une fois que vous avez fait cela, cliquez sur « Suivant » pour continuer.
- Le deuxième écran de création de bucket vous permet d’activer l’une des propriétés de votre baquet de sauvegarde Amazon S3, telles que les balises, le versionnage, le cryptage, la journalisation de l’accès au serveur et la journalisation au niveau des objets. Afin de garder cette explication simple, nous n’activerons aucune de ces propriétés. Cliquez sur « Suivant » pour continuer.
- L’écran suivant permet de personnaliser les autorisations, y compris les autorisations du système et les autorisations des utilisateurs. Vous pouvez également modifier vos propres niveaux d’autorisation et ajouter des personnes spécifiques pour avoir accès à ce bucket. Notre exemple conserve tous les niveaux de permission par défaut – avec le créateur ayant accès à tout ce qui se trouve dans ce bucket. Cliquez sur « Suivant » lorsque vous avez terminé.
- La dernière partie du processus est l’écran de confirmation, qui vous permet de revoir tous les paramètres que vous avez précédemment configurés. Cela inclut les permissions, les propriétés et les noms. En cliquant sur le bouton « Créer un bucket » après avoir terminé le processus de révision, vous faites exactement ce qu’il dit – vous créez un bucket avec vos paramètres spécifiques.
- Télécharger un fichier.
- Le téléchargement d’un fichier vers votre nouveau bucket AWS S3 est également relativement facile, si vous commencez à partir de la console Amazon S3. En cliquant sur le nom de votre nouveau bucket AWS, vous pourrez accéder à ce bucket et à son contenu.
- Dès que vous êtes sur la page d’accueil de votre bucket, vous pouvez lancer le processus de téléchargement en cliquant sur le bouton « Télécharger » dans la partie gauche de la page.
- Il y a deux façons de télécharger un fichier dans la fenêtre suivante – soit en glissant-déposant un fichier sur la page, soit en cliquant sur le bouton « Ajouter des fichiers » et en sélectionnant le fichier en question ensuite. Une fois que vous avez choisi le fichier à télécharger, vous pouvez cliquer sur « Suivant » pour continuer.
- Comme pour le processus de création du bucket S3 de sauvegarde, vous pouvez modifier les autorisations du fichier avant de le télécharger, y compris à la fois vos propres autorisations, les comptes qui ont accès à ce fichier et les autorisations publiques. Utilisez le bouton « Suivant » pour continuer.
- La page suivante concerne davantage les propriétés spécifiques de votre fichier, telles que la classe de stockage (Standard, Standard-IA et Redondance réduite), le cryptage (Aucun, Clé maîtresse S3 et Clé maîtresse KMS) et les métadonnées. Une fois que vous avez choisi l’une des options, vous pouvez continuer en cliquant sur le bouton « Suivant ».
- Le dernier écran de cette séquence consiste à confirmer tous vos changements avant le téléchargement.
- Restauration d’un fichier.
- Le téléchargement d’un fichier à partir de votre bucket AWS S3 peut se faire en deux étapes simples. Tout d’abord, vous devez vous trouver sur la page d’accueil de votre bucket, sur laquelle vous verrez tous les fichiers qui y sont stockés. La première étape consiste à cliquer sur le champ coché à gauche du fichier que vous souhaitez télécharger.
- La sélection d’au moins un fichier de la liste fait apparaître une fenêtre pop-up de description, qui comporte deux boutons : « Télécharger » et « Copier le chemin ». Utilisez le bouton « Télécharger » pour recevoir le fichier en question.
- Suppression d’un fichier ou d’un bucket.
- La suppression de fichiers ou même de buckets inutiles n’est pas seulement facile, elle est aussi fortement recommandée par Amazon lui-même pour éviter un encombrement excessif de vos fichiers. Tout d’abord, le processus de suppression de fichier.
- Dès que vous arrivez sur la page de destination d’un bucket, la première chose à faire est de cliquer sur la case à cocher à gauche du fichier que vous souhaitez supprimer.
- Après avoir choisi le ou les fichiers à supprimer, vous pouvez appuyer sur le bouton « Plus » près des boutons « Télécharger » et « Créer un dossier » et choisir l’option « Supprimer » dans la liste déroulante.
- Vous recevrez un écran de confirmation qui vous montrera les fichiers à supprimer, et vous devrez cliquer sur « Supprimer » une fois de plus pour lancer le processus de suppression.
- Le processus de suppression d’un bucket entier est légèrement différent. Tout d’abord, vous devez quitter la page de destination de votre bac et revenir à la console principale de sauvegarde Amazon S3 qui répertorie tous vos bacs.
- Cliquez sur l’espace vide à droite du seau que vous voulez supprimer pour sélectionner le seau, et cliquez sur le bouton « Supprimer le bucket » pour lancer le processus de suppression.
Il convient de noter que toutes ces opérations de base pourraient être effectuées avec le seul système d’Amazon et sans l’ajout d’une quelconque solution de sauvegarde AWS.
Autres méthodes de sauvegarde de votre bucket Amazon S3
L’utilisation d’AWS Backup n’est pas la seule option lorsqu’il s’agit de sauvegardes S3. Il existe une variété d’options différentes qui peuvent être réalisées par une application au sein de l’écosystème d’Amazon ainsi que par des solutions tierces.
Par exemple, voici plusieurs autres façons de créer une sauvegarde S3 sans utiliser l’application AWS Backup :
- Créer des sauvegardes à l’aide d’Amazon Glacier ;
- Utiliser AWS SDK pour copier un seau S3 vers un autre ;
- Copier des informations sur le serveur de production qui est lui-même sauvegardé ;
- Utiliser le versioning comme service de sauvegarde.
Il convient de mentionner que la plupart de ces méthodes ne sont pas exactement rapides ou pratiques. Amazon Glacier, par exemple, serait une bonne solution de sauvegarde si elle n’était pas beaucoup plus lente que votre processus de sauvegarde habituel, car Glacier est plus axé sur l’archivage des données et moins sur les sauvegardes de données en continu. D’un autre côté, l’utilisation du versioning comme solution de sauvegarde pourrait augmenter considérablement vos coûts de stockage en raison de la quantité de données à stocker.
En ce qui concerne les solutions tierces, bien qu’il en existe un grand nombre sur le marché, nous allons examiner l’une des plus prometteuses – la solution fournie par Bacula Enterprise.
Solutions de sauvegarde AWS S3 de qualité professionnelle avec des coûts de restauration minimes.
Bacula propose des solutions de sauvegarde AWS S3 intégrées en natif dans le cadre de ses options de sauvegarde et de restauration basées sur le cloud. Il offre une intégration native avec les clouds publics et privés via l’interface Amazon S3, avec un support transparent de S3-IA. La sauvegarde AWS S3 est disponible pour Linux, Windows et d’autres plateformes. Cependant, il y a autre chose que votre entreprise devrait savoir sur la sauvegarde Amazon S3 avec Bacula Enterprise : la possibilité d’avoir un contrôle unique sur votre sauvegarde dans le cloud – et en même temps d’apporter une réduction significative des coûts du cloud pour les solutions de sauvegarde AWS.
Sauvegarde AWS S3 avec Bacula Enterprise
Pour commencer le processus de sauvegarde AWS avec Bacula, vous devez d’abord entrer en mode configuration. Ensuite, vous verrez plusieurs nouvelles options disponibles. Vous avez besoin de celle intitulée « Ajouter une nouvelle ressource de stockage ».
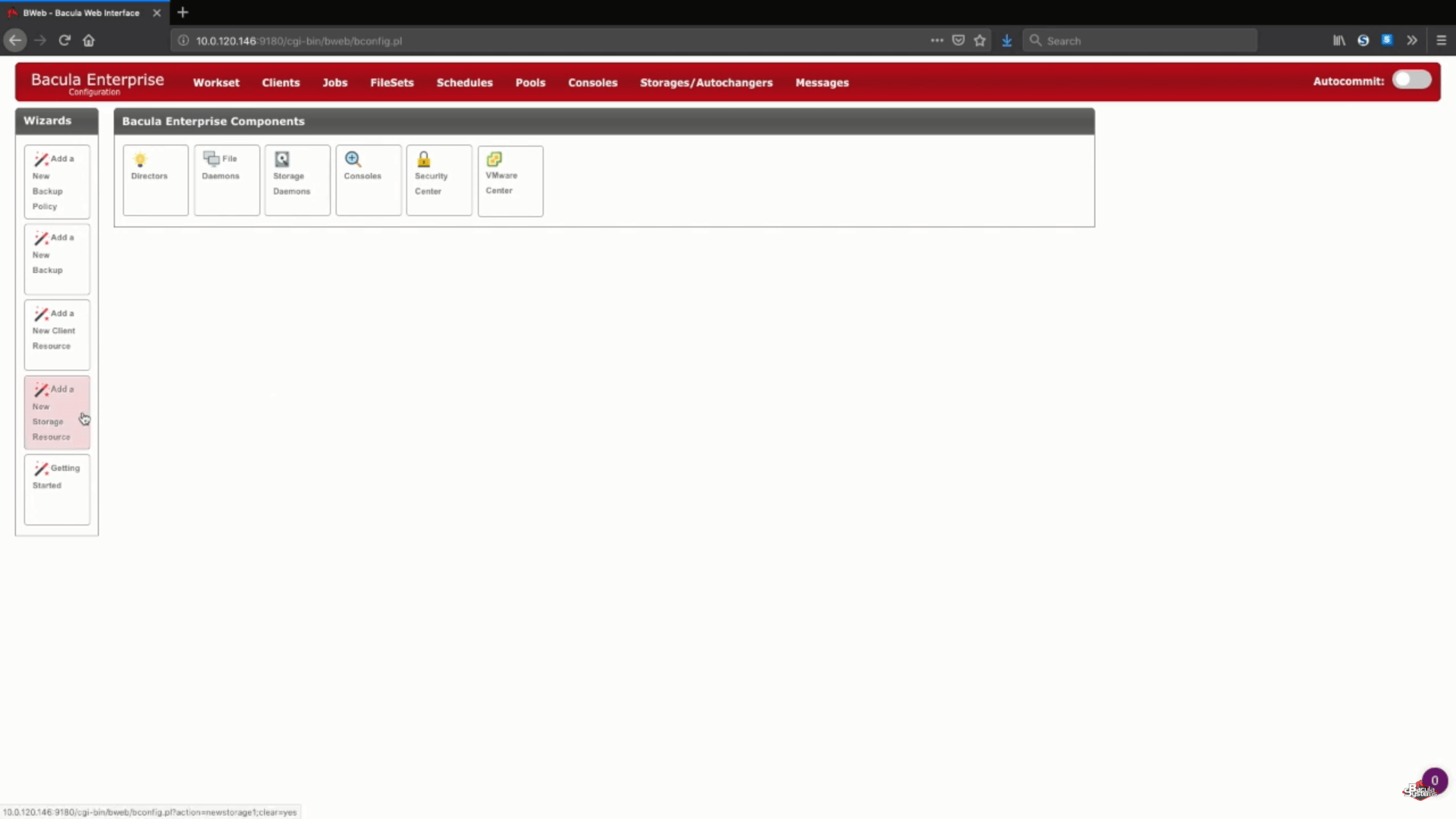
Ajout d’un nouveau stockage S3 dans Bacula Enterprise
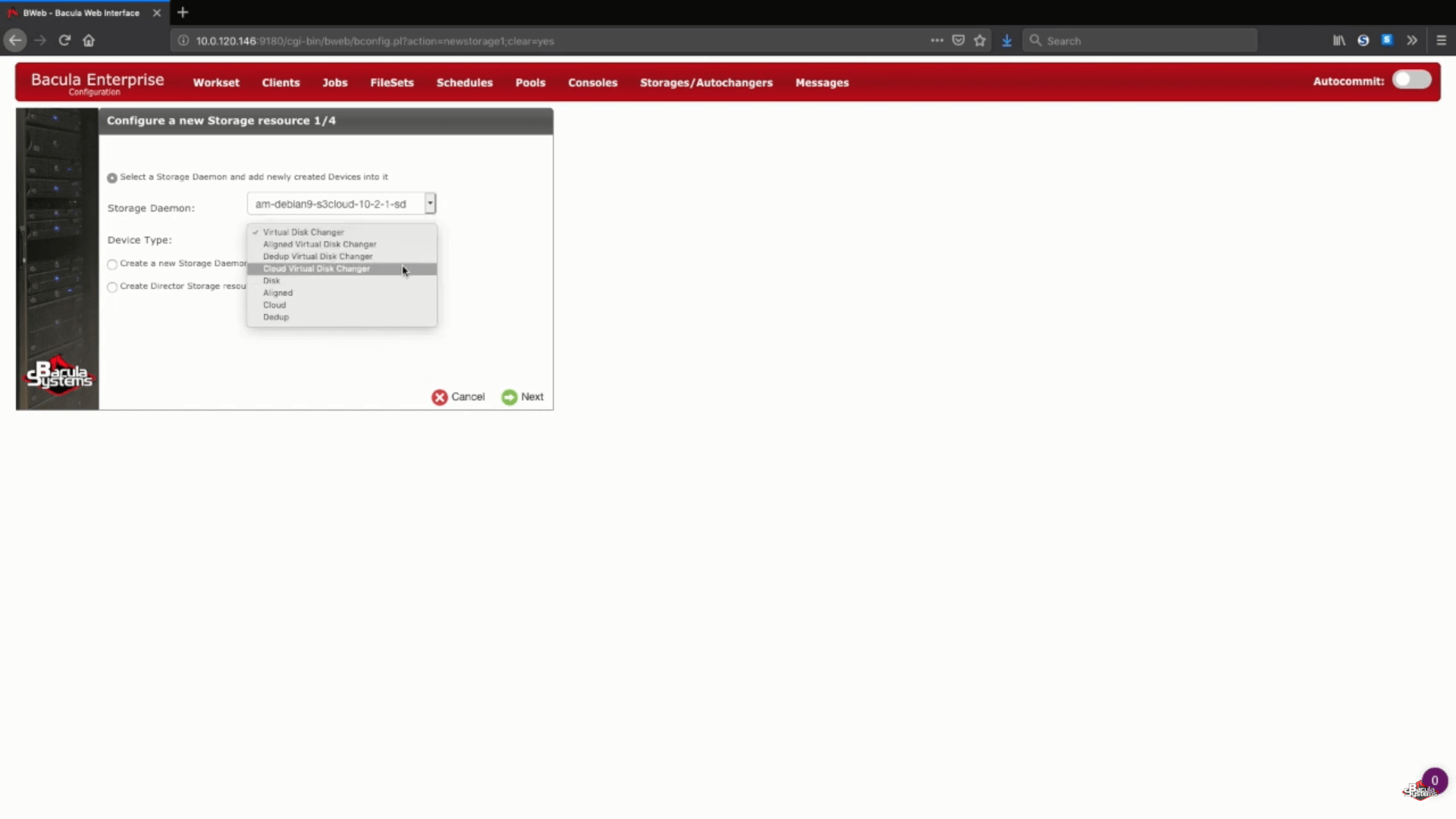
Dans cet exemple spécifique, nous allons ajouter un nouveau stockage Amazon S3 à un démon de stockage existant. Nous choisirons également le « Cloud Virtual Disk Changer » sous le « Device Type » – ce type de dispositif permet de réaliser plusieurs sauvegardes simultanées sur le même stockage en nuage.
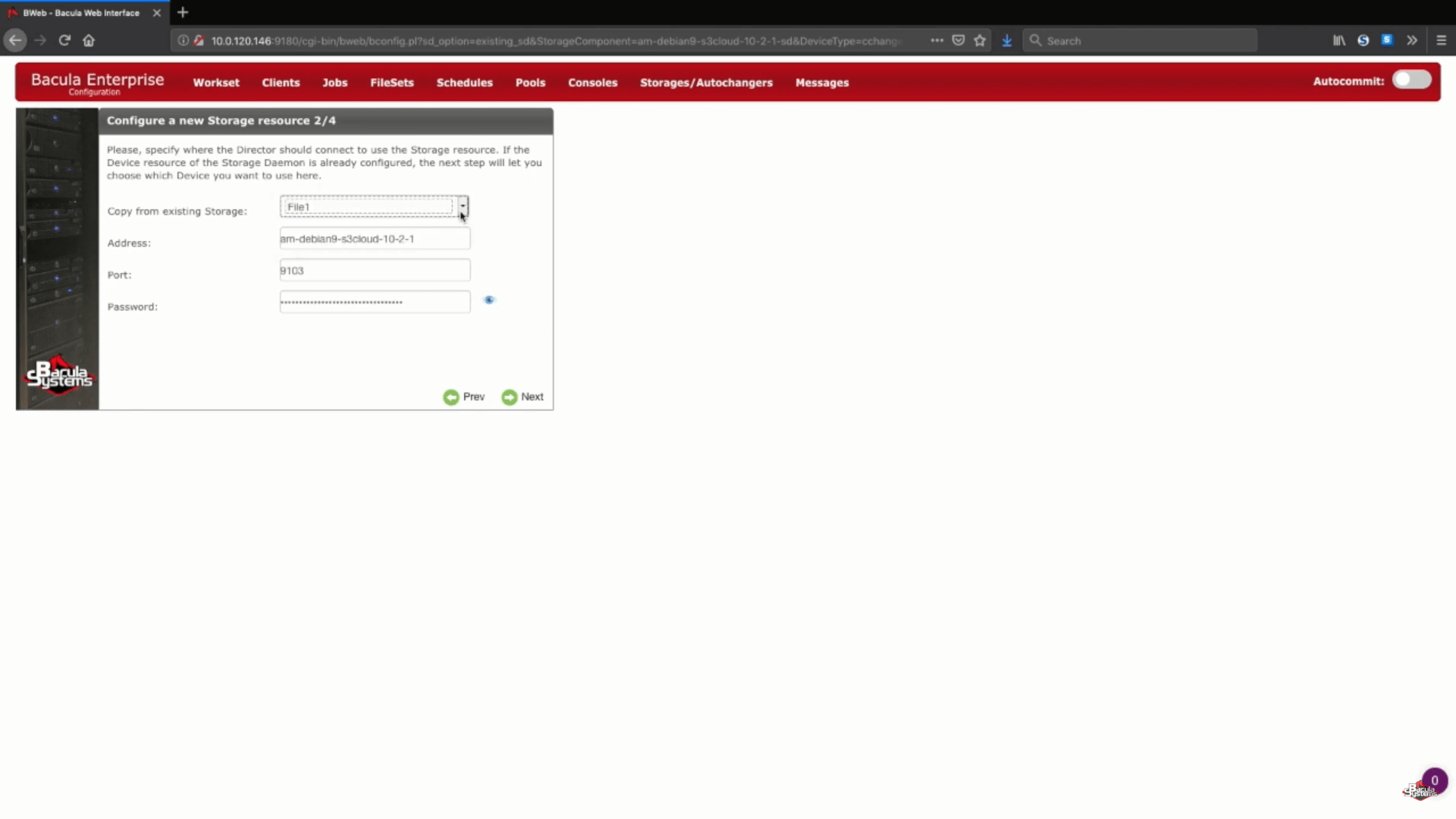
Puisque notre daemon de stockage existe déjà – toutes les informations de l’étape 2 (Configuration d’une nouvelle ressource de stockage) peuvent être reprises des dispositifs précédemment créés.
Configuration de votre sauvegarde du stockage AWS S3 avec Bacula Enterprise
L’étape suivante du processus de sauvegarde AWS est la configuration des informations de stockage dans le cloud. Dans cet exemple, nous allons stocker nos volumes de sauvegarde dans le cache du cloud, qui est généralement utilisé comme une petite zone temporaire entre le chargement d’une sauvegarde dans le cloud, mais qui peut toujours contenir une semaine ou plus de données pour permettre des sauvegardes locales pendant cette période, et des sauvegardes dans le cloud si la période est supérieure à une semaine. Vous pouvez toujours contacter les experts du support Bacula pour en savoir plus sur la taille de stockage du cache du cloud, la politique de rétention du cache et le comportement de téléchargement du cloud.
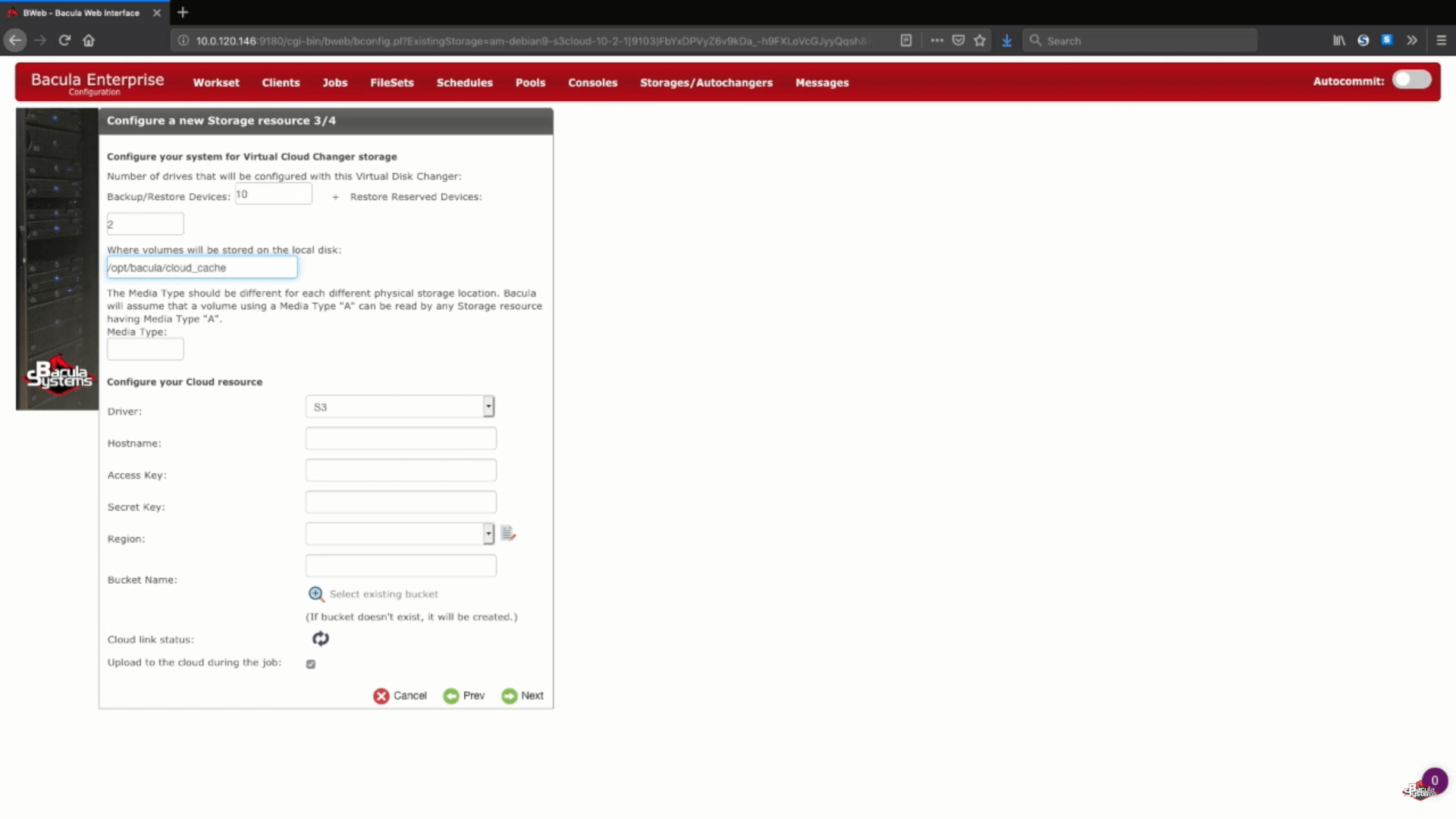
Ensuite, nous allons choisir un type de média unique pour notre nouveau périphérique de stockage, afin que Bacula puisse voir plus facilement les fichiers de ce périphérique spécifique.
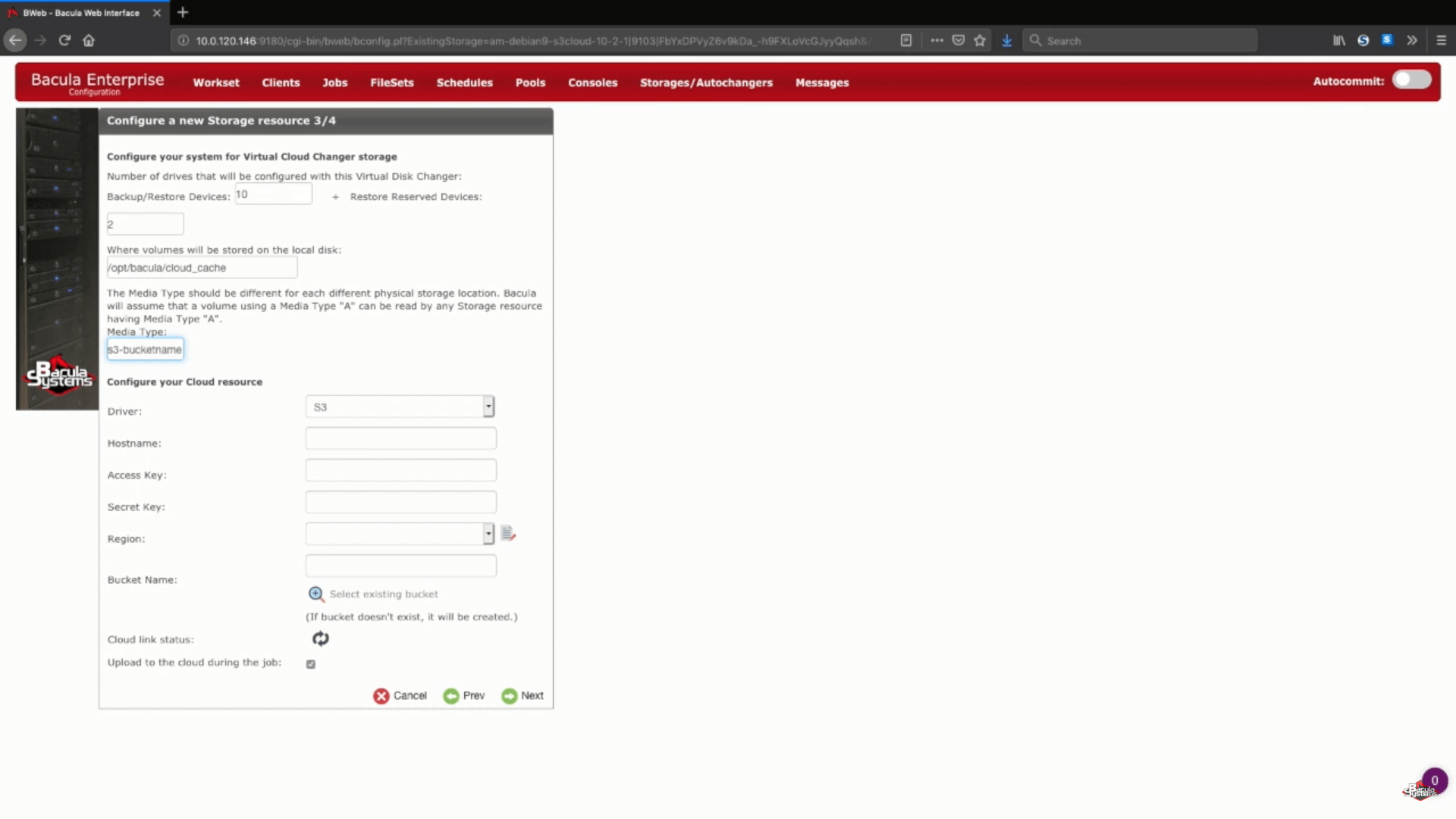
Une autre partie de cette étape consiste à choisir votre pilote de cloud AWS S3 dans une liste de pilotes de cloud supportés.
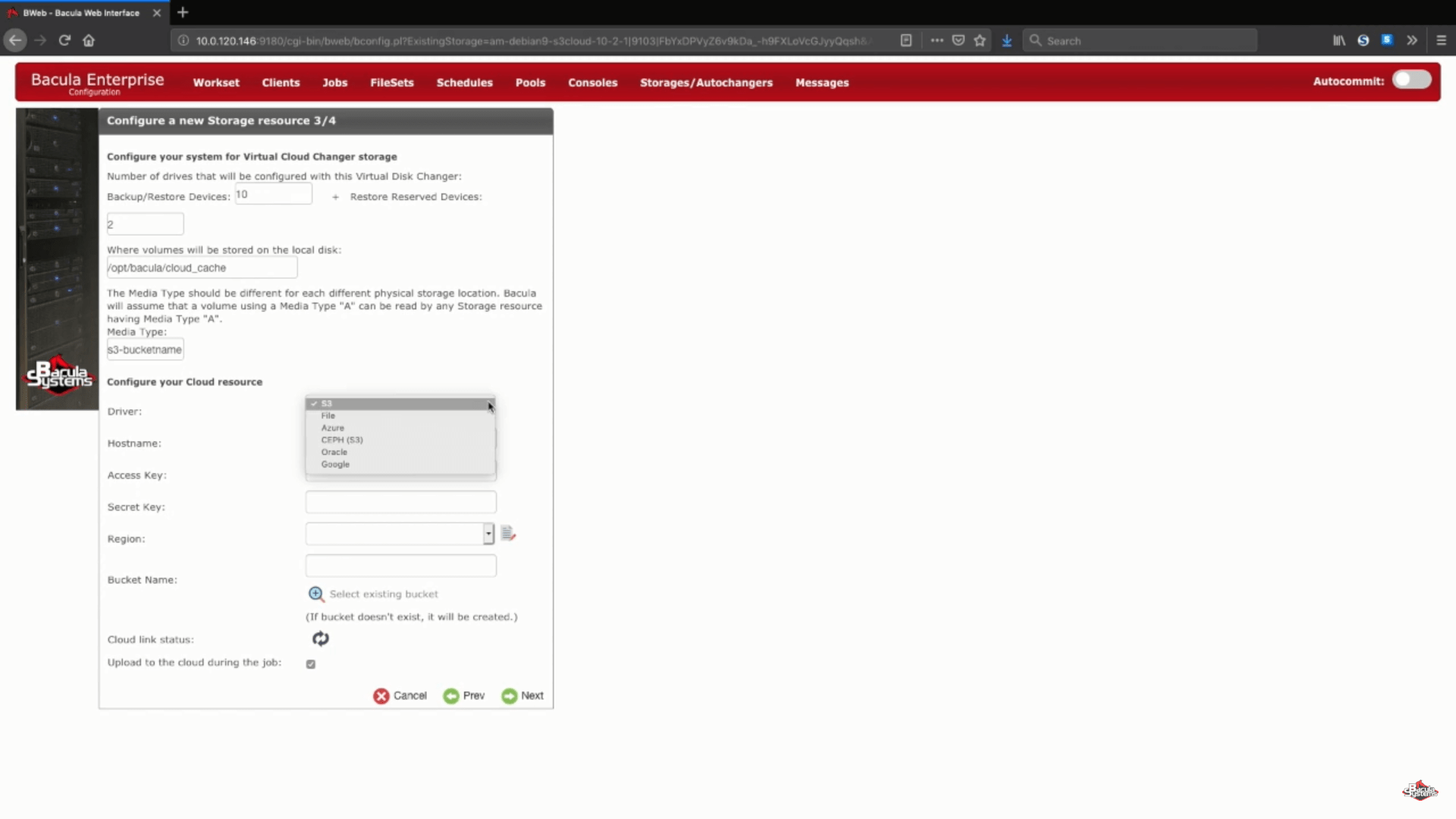
Ensuite, nous configurons une liste d’informations arbitraires comme le nom d’hôte du cloud, les informations de compte, la région, etc. Vous aurez également le choix entre choisir un bucket existant en vous connectant à votre compte existant ou saisir un nom dans la ligne correspondante pour confirmer la création d’un nouveau bucket.
Terminer le processus de configuration du stockage S3
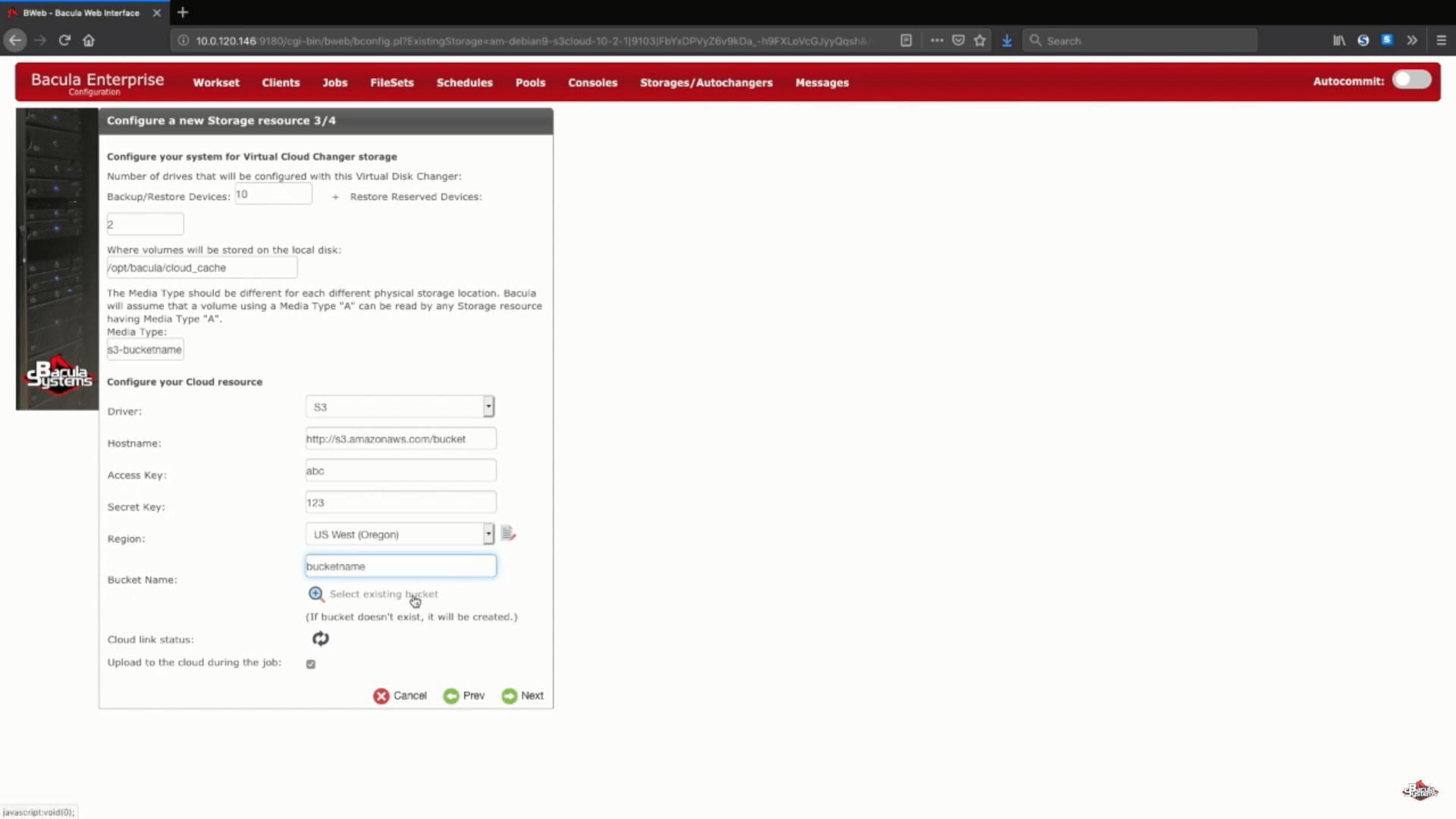
Il reste deux options possibles : statut du lien avec le cloud et « télécharger vers le cloud pendant le travail ». Le bouton « Cloud link status » vous permet de vérifier immédiatement la connexion de votre système actuel à un cloud de votre choix. « Télécharger vers le cloud pendant la tâche » est une option qui est choisie dans le cadre des paramètres par défaut pour télécharger vos données sauvegardées vers le nuage dès qu’elles sont prêtes (même au cours d’une tâche de sauvegarde), mais vous pouvez également désactiver cette option si vous souhaitez télécharger après la fin d’une tâche ou avec un autre calendrier en tête.
L’étape suivante de cet assistant consiste simplement à saisir le nom de votre stockage préféré et une description facultative.
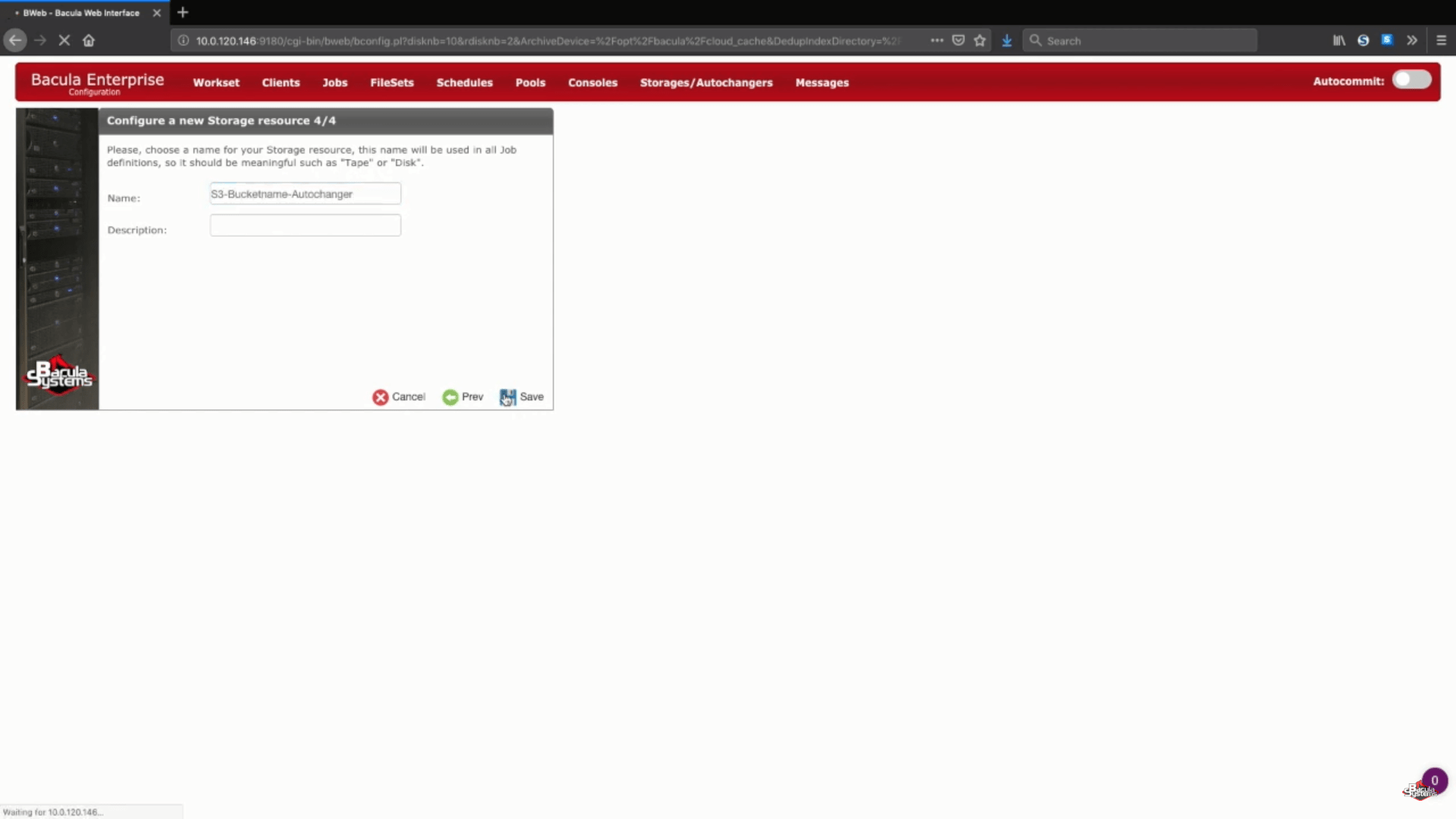
Sauvegarde de vos nouveaux paramètres de sauvegarde S3
Après cette étape, vous pouvez appuyer sur le bouton « Save » pour permettre à toutes les modifications précédentes d’être intégrées à la production. Gardez à l’esprit qu’afin de valider correctement toutes les modifications dans la production, vous devrez recharger votre démon de stockage, ce qui signifie que toute tâche en cours d’exécution échouera dans le processus.
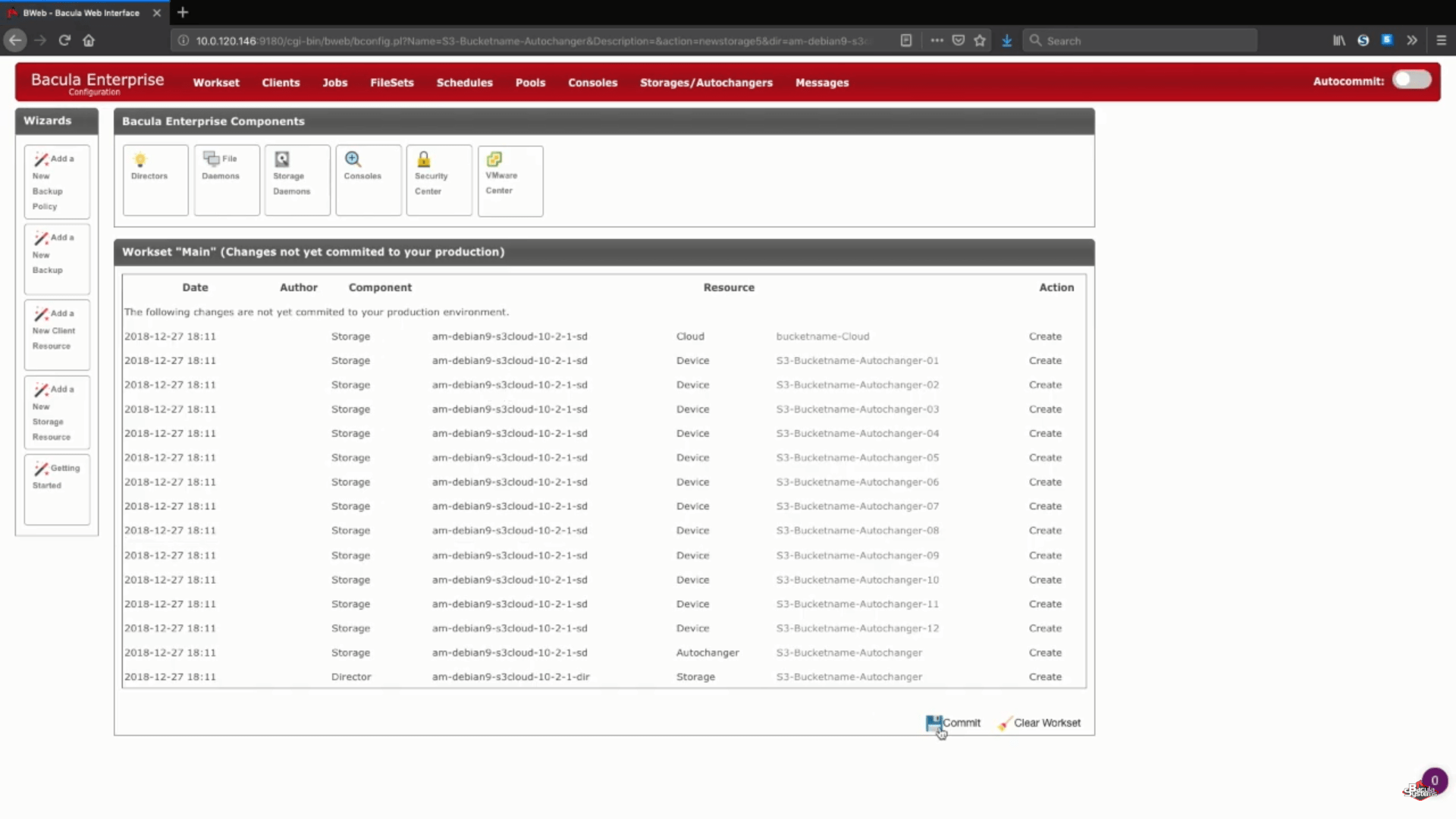
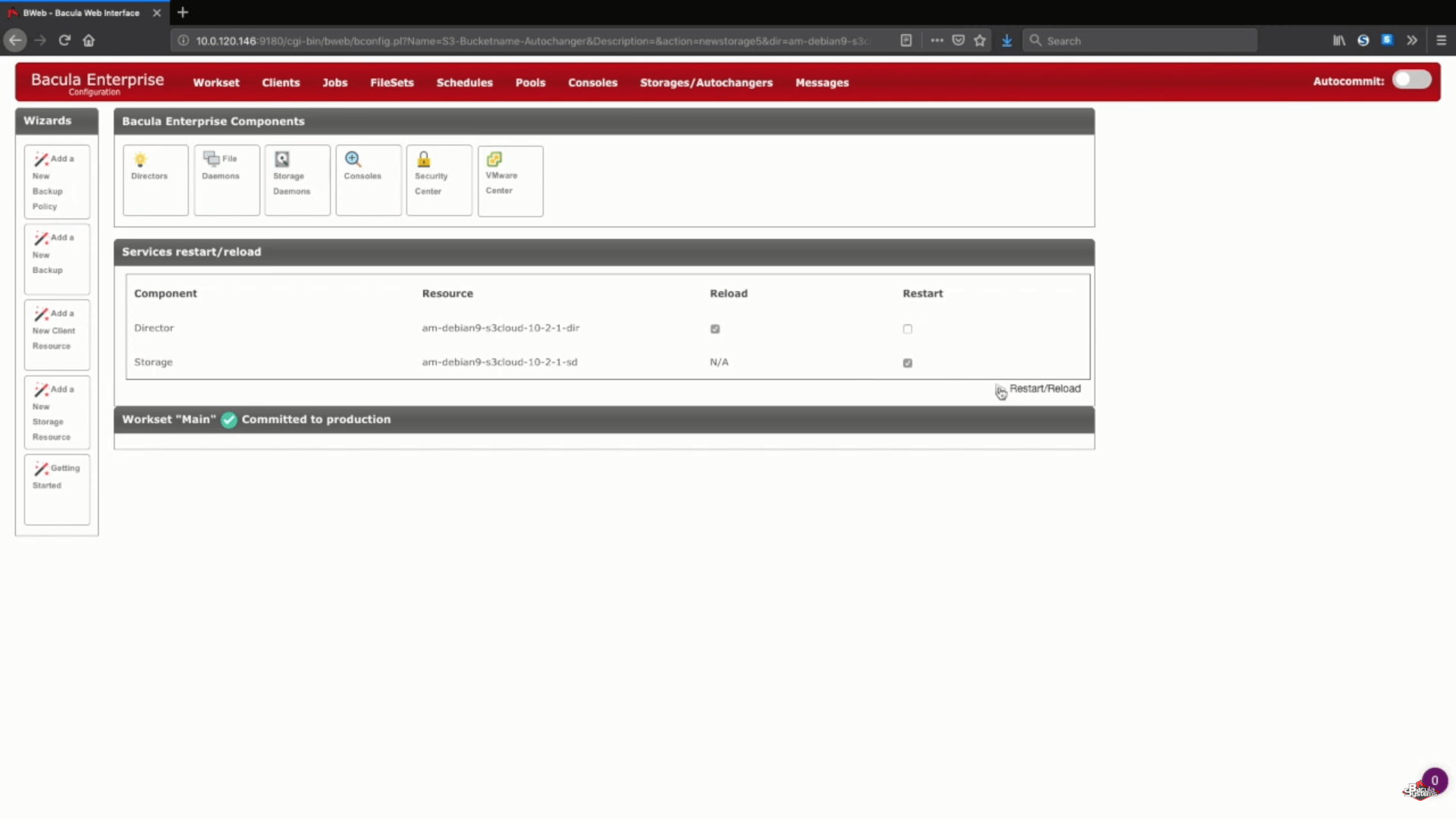
Une étape logique après cela serait de mettre en place de nouveaux pools de sauvegarde pour ce stockage en cloud spécifique et de configurer correctement les tâches pour écrire les données dans les nouveaux pools. Vous pouvez consulter la documentation de Bacula, contacter notre support ou regarder notre chaîne YouTube pour obtenir de l’aide concernant ces étapes.
Test des paramètres de sauvegarde AWS
Pour vérifier que tout ce que nous venons de faire fonctionne correctement, nous allons exécuter manuellement une petite tâche de sauvegarde complète Amazon S3 directement sur le nouveau périphérique de stockage. Habituellement, ce processus est automatisé à l’aide d’une planification des tâches et/ou d’autres configurations.
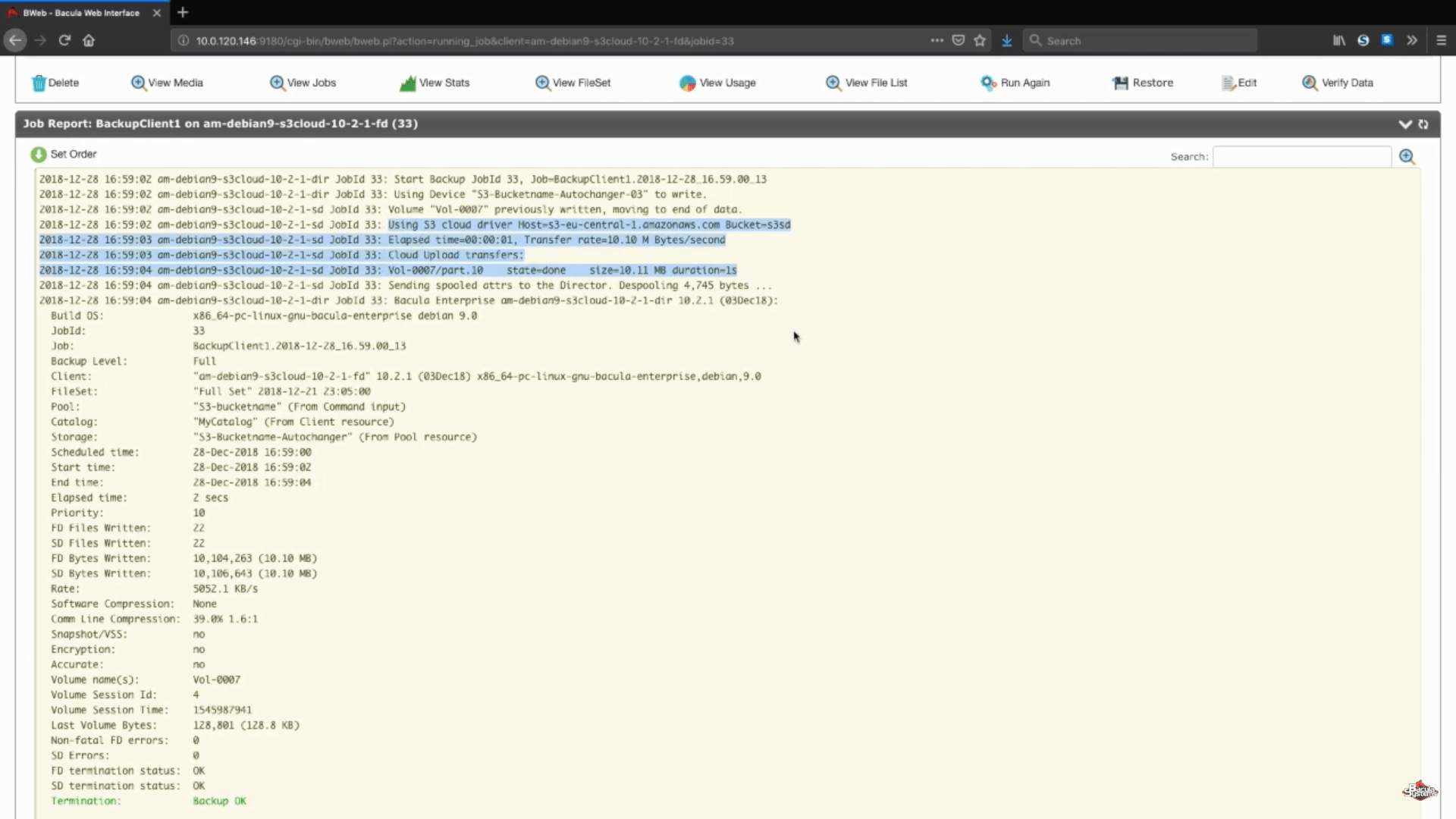
Après l’exécution de la tâche, nous pourrons voir les journaux de l’ensemble du processus, et cette section spécifique (sur la capture d’écran ci-dessous) nous montre que tout a été téléchargé correctement.
Conclusion
Bacula Enterprise est un choix judicieux pour gérer de manière fiable vos sauvegardes AWS S3 et autres clouds, y compris la création et la configuration de nouveaux stockages de sauvegarde et la configuration de tâches de sauvegarde à exécuter automatiquement. Ensuite, nous allons énumérer certaines des fonctionnalités de Bacula Enterprise spécifiques à AWS S3.

