Contents
- Utilizzare AWS Backup per creare backup
- AWS Backup e la sua interazione con altri servizi basati su AWS
- AWS backup ed EC2
- Aggiornamento 2022
- Operazioni di base con la console Amazon S3
- Altri metodi di backup del bucket Amazon S3
- Versioning e replica dei bucket
- Soluzioni di backup AWS S3 di livello enterprise con costi minimi di ripristino.
- AWS S3 Backup con Bacula Enterprise
- Aggiungi un nuovo storage S3 in Bacula Enterprise
- Configurazione del backup dello storage AWS S3 con Bacula Enterprise
- Concludere il processo di configurazione dello storage S3
- Salvare le nuove impostazioni di backup S3
- Test delle impostazioni di backup AWS
- Conclusione
Utilizzare AWS Backup per creare backup
Il backup delle informazioni – i dati – è forse la parte più importante per proteggerli da qualsiasi danno e per garantire la conformità. Anche i server e gli archivi più resistenti sono suscettibili di bug, errori umani e altre possibili cause di disastro. Ma creare e gestire tutti i flussi di lavoro di backup potrebbe essere un compito scoraggiante. Pertanto, esistono diversi metodi che può utilizzare per semplificare l’intero processo di creazione di un backup utilizzando AWS S3.
Una scelta popolare è la soluzione di backup di Amazon, AWS Backup. AWS Backup può fornire un modo per gestire i suoi backup sia nel cloud AWS che in sede, oltre a supportare una serie di altre applicazioni Amazon.
Il processo di backup in sé è abbastanza semplice. Un utente deve creare una politica di backup – il suo piano di backup – specificando una serie di parametri come la frequenza di backup, la quantità di tempo in cui questi backup devono essere conservati, ecc. Non appena la politica è stata impostata, AWS Backup dovrebbe iniziare a eseguire automaticamente il backup dei suoi dati. Dopodiché potrà utilizzare la console di AWS Backup per visualizzare le risorse sottoposte a backup, avere l’opzione di ripristinare un backup specifico o semplicemente monitorare l’attività di backup e ripristino.
AWS Backup e la sua interazione con altri servizi basati su AWS
Ci sono molti servizi AWS diversi che possono offrire varie funzioni utili e lavorare in tandem con il servizio AWS Backup. Ad esempio, questi servizi includono, ma non sono esclusivi:
- Amazon EBS (Elastic block store);
- Amazon RDS (Servizio di database relazionale);
- Backup di Amazon DynamoDB;
- Istantanee del gateway di archiviazione AWS, ecc.
Naturalmente, deve abilitare il servizio specifico che desidera utilizzare nel suo processo di backup prima di utilizzarlo. Cercare di avviare o creare il backup utilizzando risorse specifiche da un servizio che deve ancora abilitare significa che probabilmente riceverà un messaggio di errore e non sarà in grado di eseguire il processo di creazione.
Per trovare l’elenco dei servizi che può attivare o disattivare, deve seguire una serie di passaggi:
- Apra la console di backup di AWS.
- Entri nel menu “Settings”.
- Si sposti alla pagina “Service opt-in” e clicchi su “Configure resources”.
Questo dovrebbe portarla alla pagina con una serie di nomi di servizi e di toggle, e potrà facilmente attivare o disattivare ciascuno dei servizi specifici. Facendo clic su “Confirm” dopo aver apportato le modifiche, salverà le operazioni.
AWS backup ed EC2
AWS backup è in grado di implementare molte funzionalità dei servizi AWS esistenti nel processo di creazione di un backup. Un buon esempio è la funzionalità di snapshot EBS, che viene utilizzata per creare backup in base al piano di backup creato. La creazione di istantanee EBS, d’altra parte, può essere effettuata utilizzando l’API EC2 (Elastic compute cloud). In questo modo potrà gestire i backup da una console di backup AWS centralizzata, monitorarli, programmare diverse operazioni e così via.
AWS backup può eseguire lavori di backup su intere istanze EC2, consentendo di non dover interagire con il livello di archiviazione stesso. Anche il funzionamento è piuttosto semplice: AWS backup esegue un’istantanea del volume di archiviazione EBS principale, nonché dei volumi associati e delle configurazioni di lancio. Tutti i dati vengono archiviati nel formato di immagine specifico chiamato volume-backed AMI (Amazon machine image).
I file di backup EC2 AMI possono anche essere crittografati durante il processo di backup, nello stesso modo in cui AWS backup lo fa con le istantanee EBS. Può utilizzare la chiave KMS predefinita, se non ne possiede una, oppure può utilizzarne una propria da applicare al backup.
Questo processo è di gran lunga superiore e più facile da personalizzare rispetto al metodo integrato di AWS EC2 per il backup e il ripristino dei dati. Ad esempio, il processo di backup per EC2 crea inizialmente un’istantanea del volume, che richiede poca o nessuna configurazione, e basta. Può farlo all’interno della console di Amazon EC2 in “Snapshots > Create Snapshot > *scelga il volume in questione* > Create”.
Il processo di ripristino delle risorse EC2 può essere eseguito in diversi modi: Console di backup AWS, linea di comando o semplicemente API. Rispetto agli altri due, la console di backup ha molti limiti di funzionalità per il processo di ripristino e non può ripristinare diversi parametri come gli indirizzi ipv6, alcuni ID specifici e così via. Gli altri due metodi, invece, sono in grado di eseguire un ripristino completo in un modo o nell’altro.
È anche possibile ripristinare i volumi EBS da un’istantanea. Tuttavia, questo processo è un po’ più complicato e comprende due parti: il ripristino di un volume da un’istantanea e il collegamento di un nuovo volume a un’istanza.
Il ripristino del volume è piuttosto semplice e può essere eseguito nella pagina EC2 andando su ELASTIC BLOCK STORE, Snapshots > *selezionare l’istantanea in questione* > Crea volume. Collegare un volume appena ripristinato ad un’istanza, invece, è un processo leggermente diverso che può eseguire andando su Volumes > Actions > Attach Volume > *scegliere il volume per nome o per ID* > Attach. Si raccomanda inoltre di mantenere il nome del dispositivo suggerito durante questo processo.
Aggiornamento 2022
Dall’inizio del 2022, AWS Backup ha aggiunto un altro servizio con cui può lavorare: Amazon Simple Storage Service (S3). Il mondo moderno ha molti requisiti e possibilità quando si tratta di opzioni di archiviazione, ed è abbastanza normale affidarsi a più sedi o servizi di archiviazione diversi contemporaneamente.
Questo tipo di integrazione consente ad AWS Backup di proteggere e governare i dati S3, proprio come fa con altri servizi Amazon. Ci sono tre vantaggi principali quando si tratta di utilizzare l’integrazione tra AWS Backup e Amazon S3:
- Migliore conformità, con i dashboard integrati;
- Processo di ripristino più semplice con processi di ripristino point-in-time;
- Una gestione centralizzata del backup più conveniente, che rende il controllo del ciclo di vita del backup molto più facile da gestire.
Al momento in cui scriviamo, AWS Backup for S3 è un’anteprima, ma può già offrire funzionalità di backup di base – backup point-in-time, backup periodici, ripristini e così via. Può anche essere completamente automatizzato utilizzando AWS Organizations.
Operazioni di base con la console Amazon S3
Il toolkit S3 di Amazon consente alcune operazioni di base quando si tratta di recuperare o archiviare un file specifico dal bucket. È possibile indicare quattro diverse operazioni che possono essere eseguite utilizzando solo il software di backup Amazon S3 – ma prima dobbiamo accedere alla console Amazon S3.
Può farlo accedendo alla pagina dei servizi AWS utilizzando questo link, inserendo i suoi dati di accesso dovrebbe poter accedere alla prima schermata del toolkit dei servizi AWS. Dopodiché è possibile trovare la console S3 sia andando al menu “Services” e trovando S3 lì, sia digitando “S3” nella barra di ricerca situata nella parte superiore della pagina.
- Creare un bucket S3.
- Un bucket è un tipo di contenitore che Amazon S3 utilizza per archiviare i suoi file. Un bucket può essere creato nell’interfaccia di AWS S3 cliccando sul pulsante “Create Bucket” nella schermata del titolo.
- Vale la pena notare che la pagina web avrà un aspetto diverso a seconda che abbia già creato un bucket all’interno di questo account o meno. Se ci sono altri bucket già esistenti, si troverà di fronte ad una schermata che le consentirà di gestire tali bucket, compreso il rinominarli o eliminarli del tutto.
- D’altra parte, se è la prima volta che crea un bucket all’interno di questo account di backup AWS S3, vedrà una schermata corrispondente che descrive il modo in cui creare un bucket in primo luogo. In questo caso, può utilizzare il pulsante “Create bucket” o il pulsante “Get started”, entrambi dovrebbero condurre allo stesso luogo: la schermata di creazione del bucket.
- La prima richiesta della schermata dovrebbe riguardare la creazione di un nome per il suo nuovo bucket, e il campo la informerà anche se il nome del bucket non soddisfa alcune delle norme di Amazon relative al nome del bucket stesso. Dovrà anche scegliere una regione appropriata per il suo futuro bucket. Una volta fatto questo, clicchi su “Next” per continuare.
- La seconda schermata di creazione del bucket le consente di abilitare una delle proprietà per il suo bucket di backup Amazon S3, come Tag, Versioning, Crittografia, Registrazione dell’accesso al server e Registrazione a livello di oggetto. Per mantenere questa spiegazione semplice, non abiliteremo nessuna di queste proprietà. Clicchi su “Next” per procedere.
- La schermata successiva consente di personalizzare i permessi, compresi quelli del sistema e quelli degli utenti. Può anche modificare i suoi livelli di autorizzazione e aggiungere persone specifiche che abbiano accesso a questo bucket. Il nostro esempio mantiene tutti i livelli di autorizzazione predefiniti – con il creatore che ha accesso a qualsiasi cosa all’interno di questo bucket. Clicchi su “Next” quando ha finito.
- L’ultima parte del processo è la schermata di conferma, che le consente di rivedere tutte le impostazioni precedentemente configurate. Questo include le autorizzazioni, le proprietà e i nomi. Cliccando sul pulsante “Create bucket” dopo aver terminato il processo di revisione, si crea un bucket con le sue impostazioni specifiche.
- Caricare un file.
- Anche caricare un file nel suo nuovo bucket AWS S3 è relativamente facile, se inizia dalla console Amazon S3. Cliccando sul nome del suo nuovo bucket AWS potrà accedere a tale bucket e al suo contenuto.
- Non appena si trova nella pagina di destinazione del suo secchio, può iniziare il processo di caricamento cliccando sul pulsante “Upload” nella parte sinistra della pagina.
- Esistono due modi per caricare un file nella finestra seguente: trascinando un file sulla pagina, oppure cliccando sul pulsante “Add files” e selezionando successivamente il file in questione. Dopo aver scelto il file da caricare, può cliccare su “Next” per procedere.
- Come per il processo di creazione del bucket S3 di backup, può modificare le autorizzazioni del file prima di caricarlo, includendo le proprie autorizzazioni, gli account che hanno accesso a questo file e le autorizzazioni pubbliche. Utilizzi il pulsante “Next” per continuare.
- La pagina successiva riguarda le proprietà specifiche del suo file, come la classe di archiviazione (Standard, Standard-IA e Ridondanza ridotta), la crittografia (Nessuna, chiave master S3 e chiave master KMS) e i metadati. Dopo aver scelto una delle opzioni, può continuare con il pulsante “Next”.
- L’ultima schermata di questa sequenza riguarda la conferma di tutte le modifiche prima del caricamento. Le sue proprietà, i permessi e la quantità di file scelti sono tutti spostati qui. Cliccando sul pulsante “Upload” dopo aver ricontrollato i dettagli, dovrebbe iniziare il processo di caricamento.
- Recupero di un file.
- Il download di un file dal suo bucket AWS S3 può essere effettuato in due semplici passi. Innanzitutto, deve trovarsi sulla pagina di destinazione del suo bucket, in cui vedrà tutti i file che sono archiviati all’interno di tale bucket. Il primo passo da compiere è cliccare sul campo di controllo a sinistra del file che desidera scaricare.
- Selezionando almeno un file nell’elenco, si apre una finestra pop-up di descrizione, con due pulsanti: “Download” e “Copy path”. Utilizzi il pulsante “Download” per ricevere il file in questione.
- Eliminazione di un file o di un bucket.
- L’eliminazione dei file o addirittura dei bucket non necessari non è solo facile, ma è anche altamente raccomandata da Amazon stesso per evitare un eccessivo ingombro dei suoi file. Prima di tutto, il processo di eliminazione dei file.
- Non appena arriva alla pagina di destinazione di un bucket, la prima cosa da fare è cliccare sul campo della casella di controllo a sinistra del file che desidera eliminare.
- Dopo aver scelto il file o i file da eliminare, può premere il pulsante “More” vicino ai pulsanti “Upload” e “Create Folder” e scegliere l’opzione “Delete” dall’elenco a discesa.
- Riceverà una schermata di conferma che le mostrerà quali file saranno eliminati e dovrà cliccare nuovamente su “Delete” per avviare il processo di eliminazione.
- Il processo di eliminazione di un intero bucket è leggermente diverso. Innanzitutto, dovrà uscire dalla pagina di destinazione del suo bucket e tornare alla console principale di backup Amazon S3 che elenca tutti i suoi bucket.
- Cliccando sullo spazio vuoto a destra del bucket che desidera eliminare, selezionerà il bucket e cliccando sul pulsante “Delete bucket” avvierà il processo di eliminazione.
Vale la pena notare che tutte queste operazioni di base potrebbero essere eseguite con il solo sistema di Amazon e senza l’aggiunta di alcuna soluzione di backup AWS.
Altri metodi di backup del bucket Amazon S3
L’utilizzo di AWS Backup non è l’unica opzione per quanto riguarda i backup S3. Esiste una serie di opzioni diverse che possono essere eseguite sia da un’applicazione all’interno dell’ecosistema di Amazon, sia da soluzioni di terze parti.
Ad esempio, ecco altri modi per creare un backup S3 senza utilizzare l’applicazione AWS Backup:
- Creare i backup utilizzando Amazon Glacier;
- Utilizzare l’SDK di AWS per copiare un bucket S3 in un altro;
- Copia le informazioni sul server di produzione di cui è stato eseguito il backup;
- Utilizzi il versioning come servizio di backup.
Vale la pena ricordare che la maggior parte di questi metodi non sono esattamente veloci o convenienti. Amazon Glacier, ad esempio, sarebbe una buona soluzione di backup se non fosse molto più lenta del suo normale processo di backup, dal momento che Glacier si occupa più dell’archiviazione dei dati e meno dei backup continui dei dati.
Versioning e replica dei bucket
Il versioning è un argomento che merita di essere approfondito. Il versioning degli oggetti è una funzione di Amazon S3 che consente di proteggere i dati da una serie di modifiche indesiderate, tra cui la cancellazione, la corruzione e così via – funziona creando una nuova copia di un file ogni volta che questo particolare file viene modificato in qualche modo (quando è archiviato in S3).
Il bucket S3 memorizza tutte queste diverse versioni dello stesso file, il che le dà la possibilità di accedere e ripristinare qualsiasi versione precedente. Ciò può talvolta contrastare persino l’eliminazione, in quanto l’eliminazione di una versione attuale del file di solito non influisce sulle versioni precedenti.
Vale la pena tenere presente che l’utilizzo del versioning come soluzione di backup potrebbe aumentare notevolmente i costi di archiviazione, a causa delle quantità di dati da archiviare. In questo caso, potrebbe voler configurare la politica del ciclo di vita per le versioni precedenti dei file, in modo che le copie più recenti possano sostituire quelle più vecchie, rendendo il versioning una soluzione complessivamente più conveniente.
Il versioning S3 può essere abilitato tramite la Console di gestione AWS, andando su Services > S3 (nella categoria “Storage”) > Buckets > bucket_name. Ogni bucket ha molte opzioni diverse personalizzabili, separate in più schede. Cerchiamo una scheda chiamata “Properties”.
Il versioning del bucket è una delle prime opzioni che appaiono nella scheda “Properties”. Sebbene sia disattivato per impostazione predefinita, tutto ciò che deve fare per attivarlo è selezionare “Edit” sotto l’opzione “Bucket Versioning” e cambiare “Bucket Versioning” nella finestra successiva da “Suspend” a “Enable”.
Può notare che l’abilitazione del versioning del bucket visualizza un utile suggerimento che le dice di aggiornare le regole del ciclo di vita per impostare il versioning come processo nel modo corretto. Le regole del ciclo di vita possono essere modificate nella scheda “Management” all’interno dello stesso menu dei dettagli del bucket.
Innanzitutto, deve creare una regola del ciclo di vita (pulsante “Create lifecycle rule”) – dovrà inserire un nome e scegliere l’ambito del ruolo (può essere applicato all’intero bucket o a file specifici scelti con dei filtri).
Può anche personalizzare il modo in cui questa regola si comporta in primo luogo utilizzando la parte “Lifecycle rule actions” di questo menu. Qui può impostare una serie di regole che riguardano le versioni attuali e precedenti dei file, nonché i prerequisiti per la scadenza della versione (con la sua successiva eliminazione). Dopo aver impostato tutto, non deve far altro che cliccare su “Create Rule” per generare e applicare la regola del ciclo di vita.
Sebbene il versioning possa essere ottimo per lavorare con file specifici, potrebbe non essere una scelta valida quando ci sono troppi file di cui conservare le versioni precedenti. Fortunatamente, il versioning non è l’unica alternativa in questo caso, poiché esiste anche la replica del bucket.
Questa opzione si trova nello stesso menu di prima; un’altra categoria sotto le “Lifecycle rules” chiamata “Replication rules”. Facendo clic su “Create replication rule” si aprirà una nuova pagina, con una serie di impostazioni per la futura regola di replica del bucket.
Qui può modificare il nome di una regola, definire lo stato della regola al momento della creazione (se sarà abilitata o disabilitata fin dall’inizio), selezionare un bucket di destinazione da replicare e un bucket di destinazione per archiviare la copia dell’originale. Le opzioni aggiuntive di questa pagina includono il controllo del tempo di replica, la sincronizzazione delle modifiche della replica, varie metriche di replica e altro ancora.
Anche questa opzione non è perfetta, in quanto comporta la copia dell’intero bucket, con un aumento massiccio della quantità di spazio di archiviazione consumato. Poiché la maggior parte di queste opzioni presenta problemi e carenze, potrebbe prendere in considerazione una soluzione di terze parti per le sue esigenze di backup e ripristino S3.
A proposito di soluzioni di terze parti, sebbene ne esistano molte diverse sul mercato, ne esamineremo una delle più promettenti: la soluzione fornita da Bacula Enterprise.
Soluzioni di backup AWS S3 di livello enterprise con costi minimi di ripristino.
Bacula offre soluzioni di backup AWS S3 integrate in modo nativo, come parte delle sue ampie opzioni di backup e ripristino basate sul cloud aziendale. Offre un’integrazione nativa con i cloud pubblici e privati tramite l’interfaccia Amazon S3, con supporto trasparente per S3-IA. Il backup AWS S3 è disponibile per Linux, Windows e altre piattaforme. Tuttavia, c’è qualcos’altro che la sua organizzazione dovrebbe sapere sul backup Amazon S3 con Bacula Enterprise: la possibilità di avere un controllo unico sul suo backup nel cloud – e allo stesso tempo di ridurre significativamente i costi del cloud per le soluzioni di backup AWS.
AWS S3 Backup con Bacula Enterprise
Per iniziare il processo di backup AWS con Bacula, deve innanzitutto accedere alla modalità di configurazione. Dopodiché potrà vedere diverse nuove opzioni disponibili. Ha bisogno di quella intitolata “Add a New Storage Resource”.
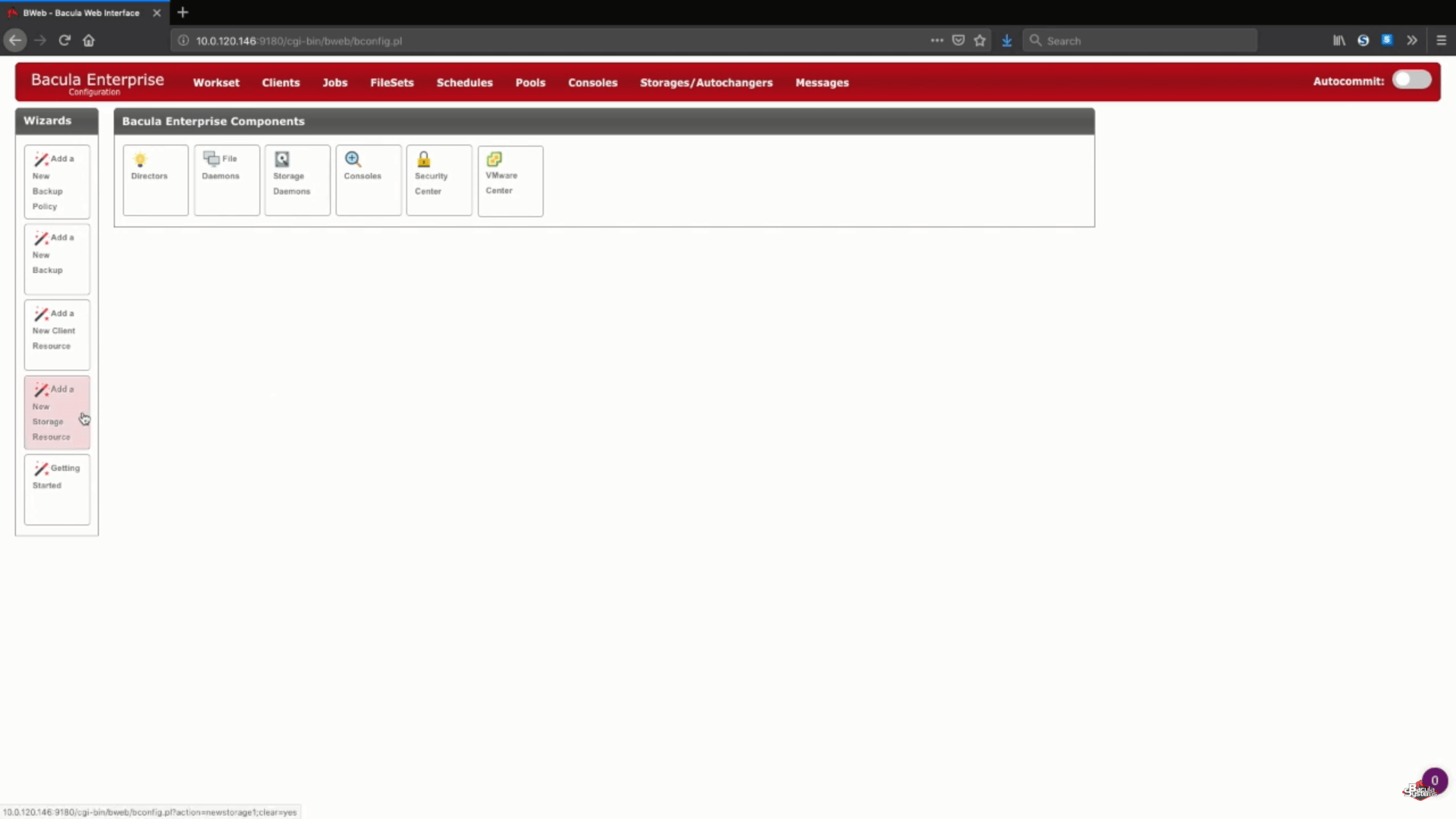
Aggiungi un nuovo storage S3 in Bacula Enterprise
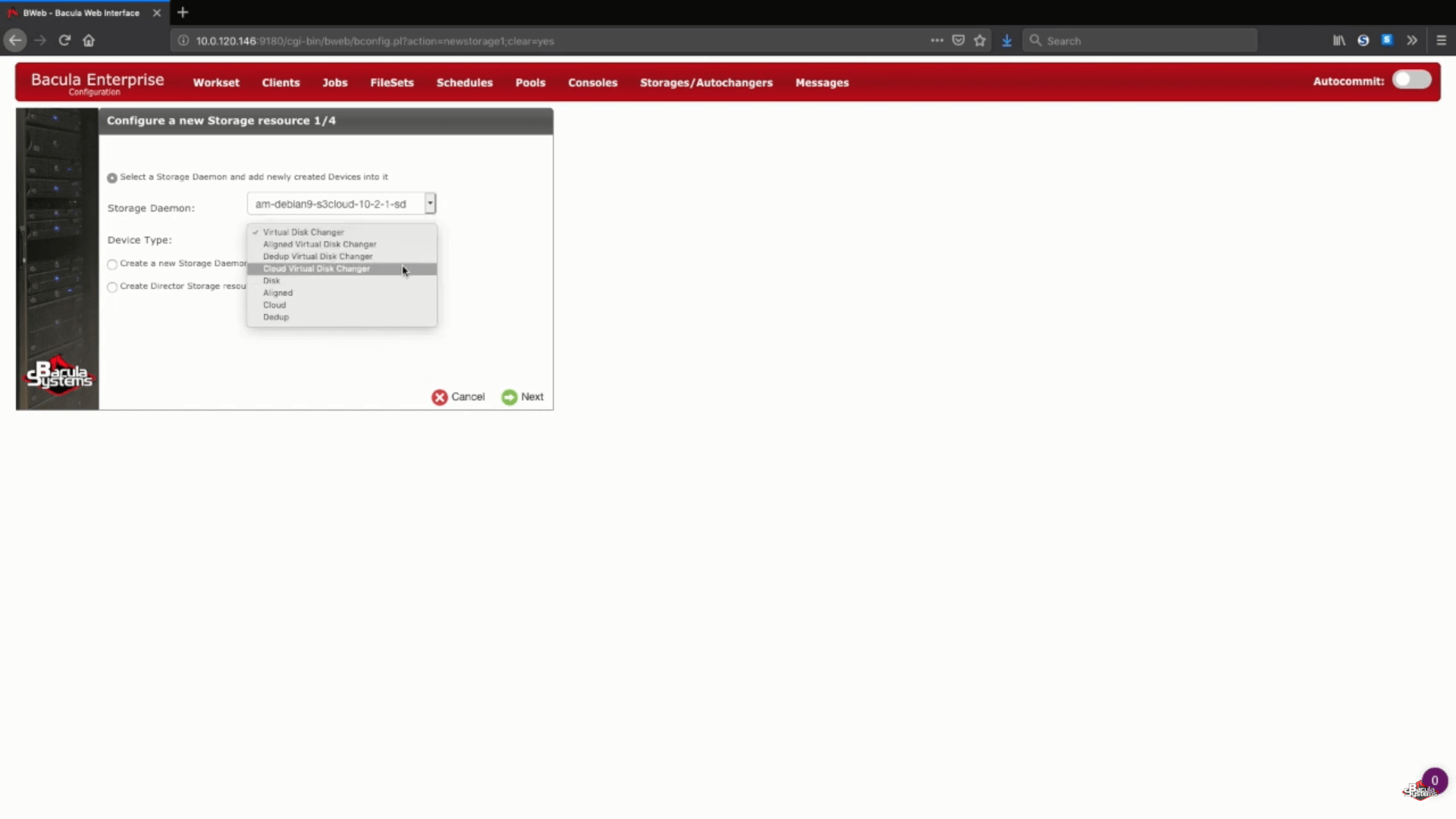
In questo esempio specifico stiamo aggiungendo un nuovo storage Amazon S3 a un demone di storage esistente. Sceglieremo anche il “Cloud Virtual Disk Changer” tra i “Device Type” – questo tipo di dispositivo consente di eseguire diversi backup simultanei sullo stesso storage cloud.
Poiché il nostro demone di archiviazione esiste già – tutte le informazioni del passo 2 (Configurazione di una nuova risorsa di archiviazione) possono essere prese dai dispositivi creati in precedenza.
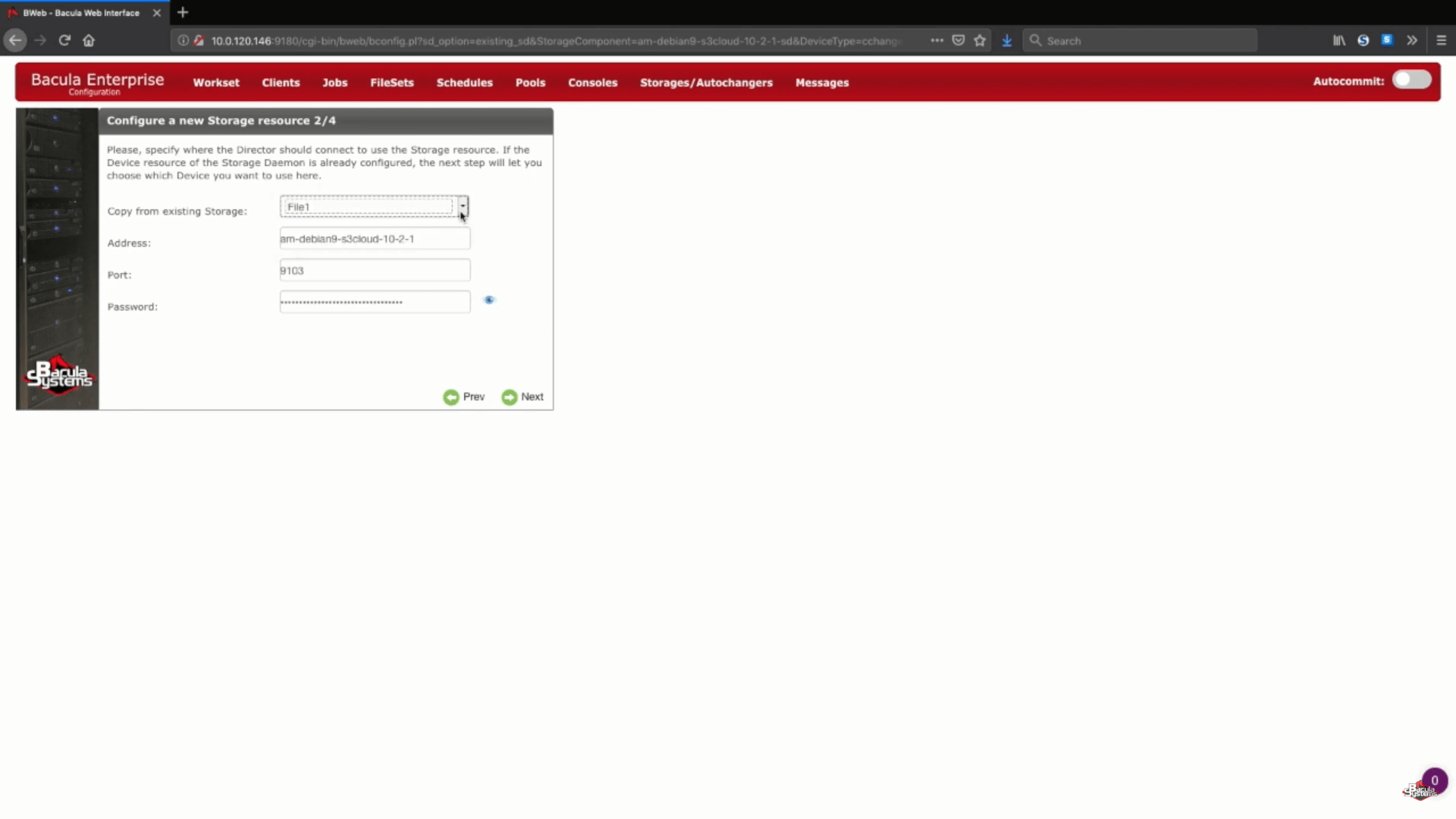
Configurazione del backup dello storage AWS S3 con Bacula Enterprise
La fase successiva del processo di backup AWS è la configurazione delle informazioni di archiviazione nel cloud. In questo esempio archivieremo i nostri volumi di backup nella cache del cloud, che di solito viene utilizzata come una piccola area temporanea tra il caricamento di un backup su un cloud, ma può comunque contenere una settimana o più di dati per consentire backup locali per quel periodo, e backup nel cloud se il periodo di tempo è più lungo di una settimana. Può sempre contattare gli esperti dell’assistenza Bacula per saperne di più sulle dimensioni di archiviazione della cache del cloud, sulla politica di conservazione della cache e sul comportamento di caricamento del cloud.
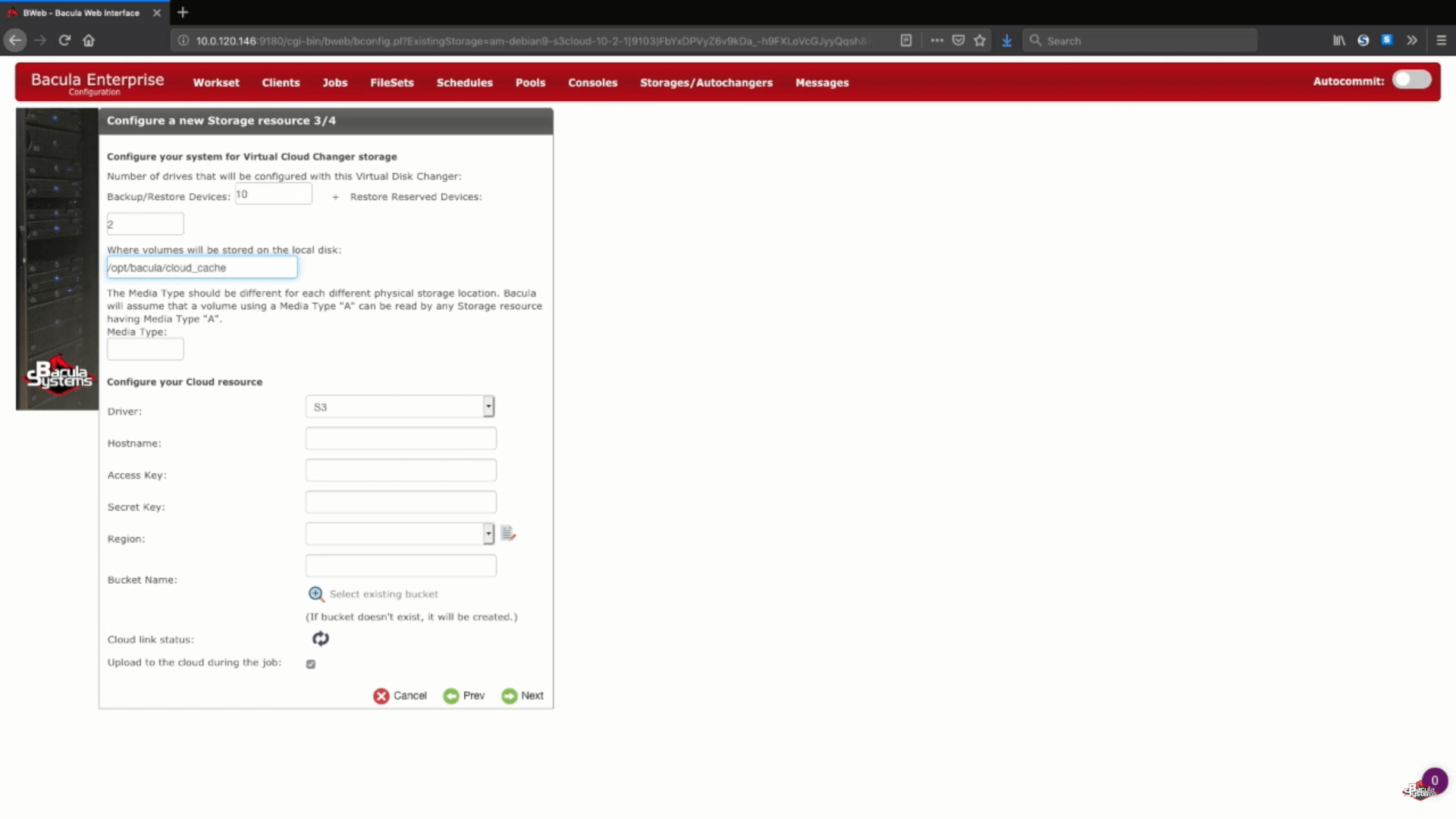
Poi sceglieremo un tipo di supporto unico per il nostro nuovo dispositivo di archiviazione, per rendere più facile per Bacula vedere i file di questo specifico dispositivo di archiviazione.
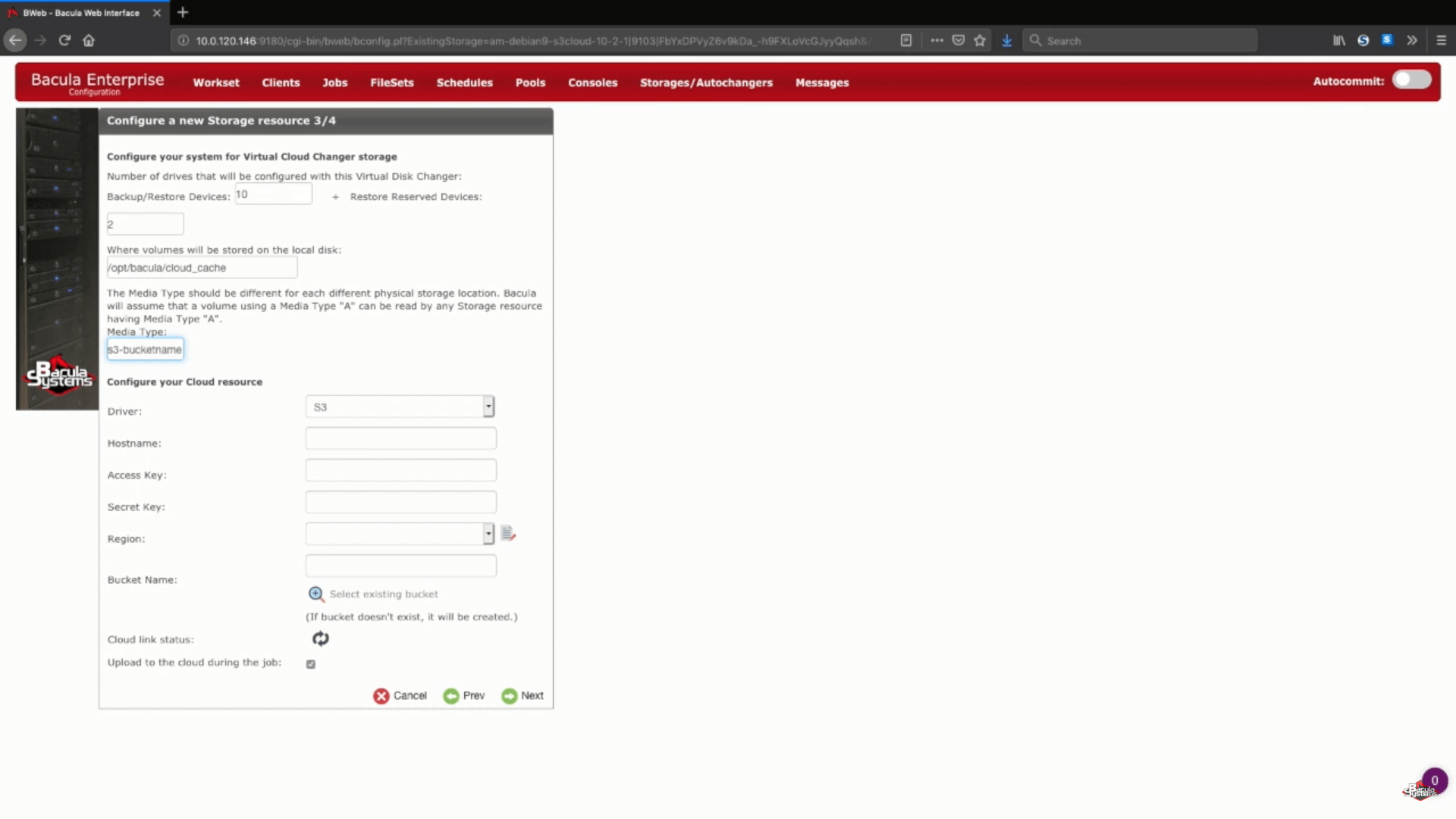
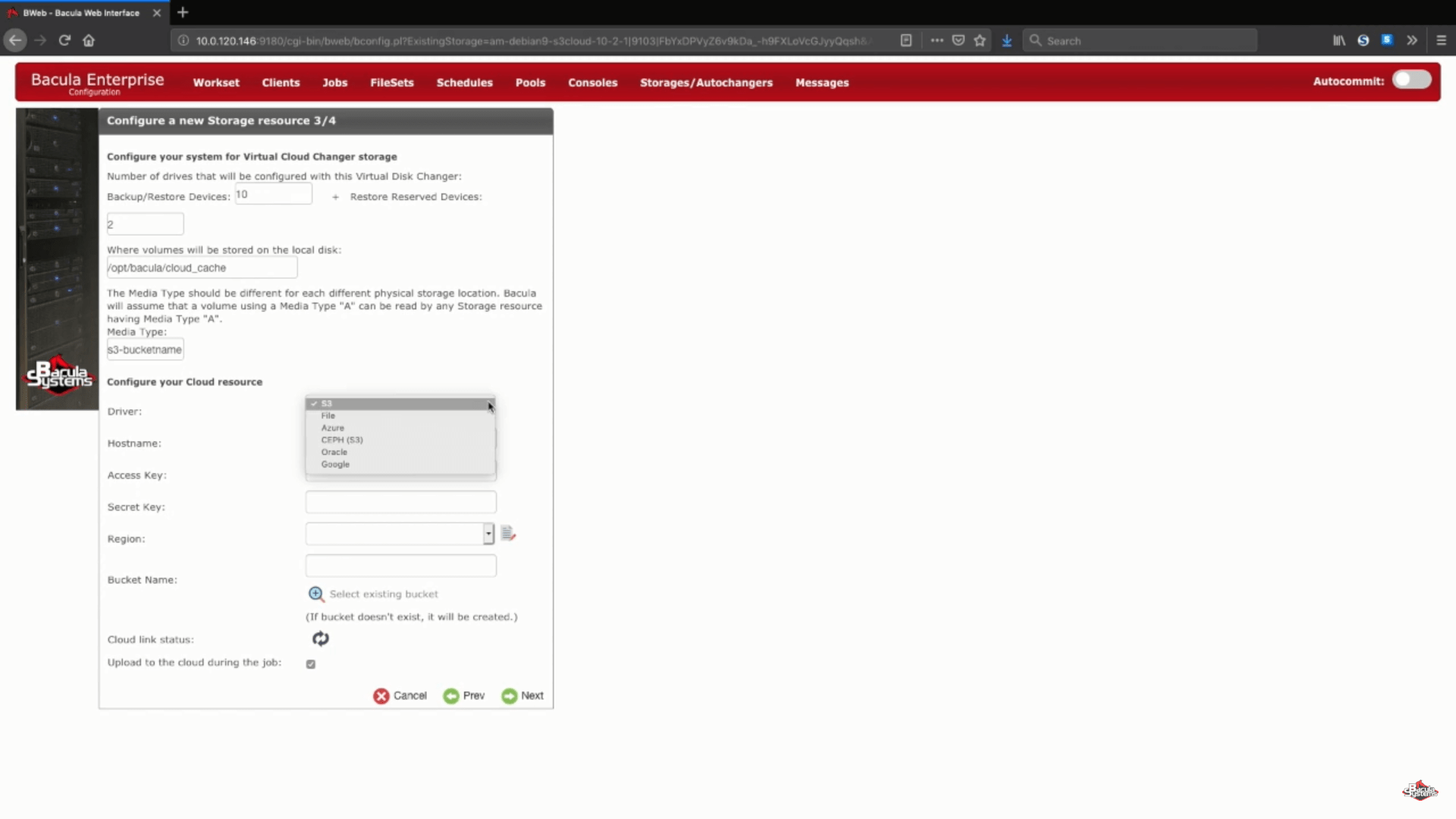
Un’altra parte di questo passaggio è la scelta del driver del cloud AWS S3 da un elenco di driver cloud supportati.
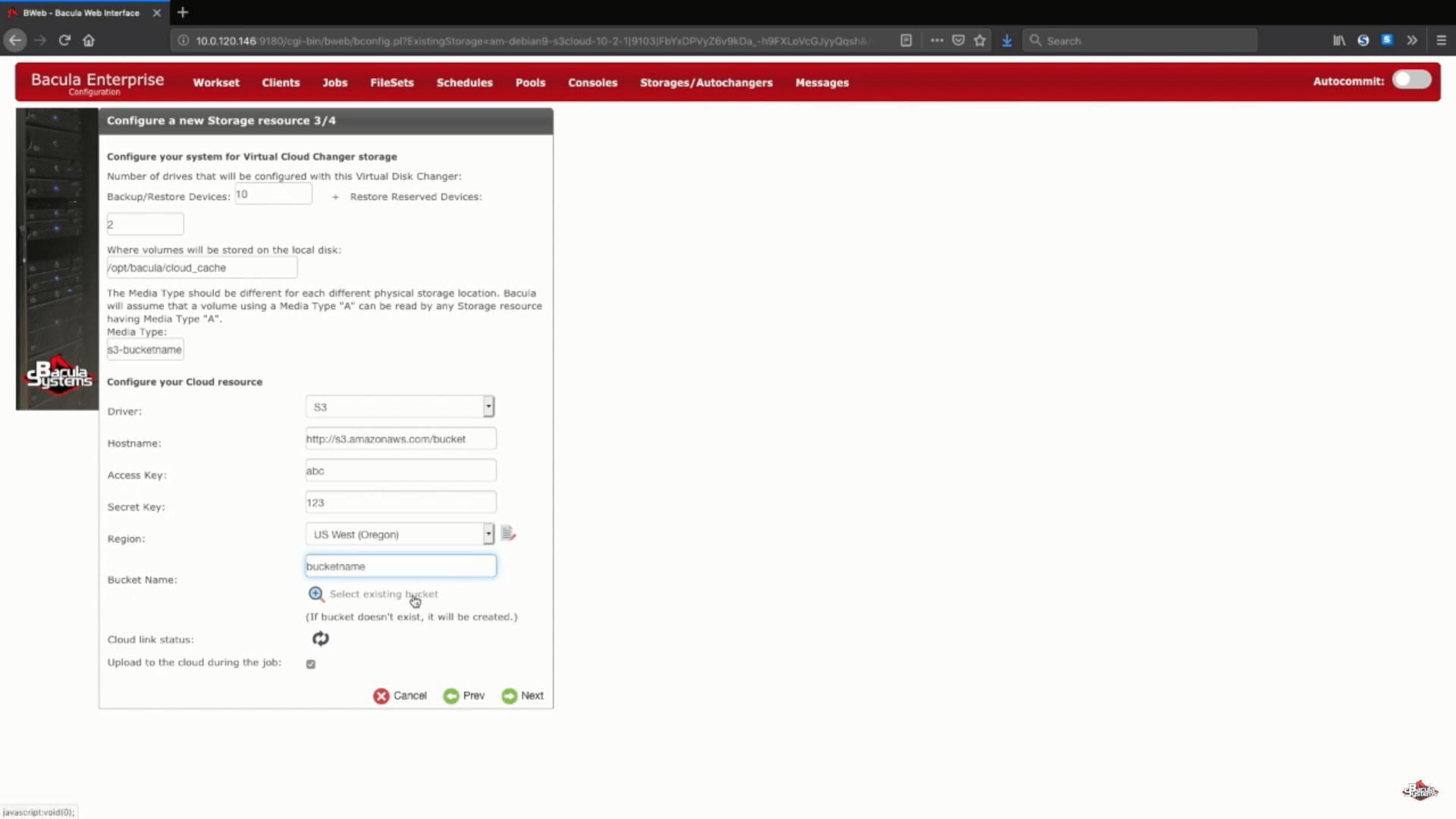
Successivamente, viene impostato un elenco di informazioni arbitrarie come il nome dell’host del cloud, le informazioni sull’account, la regione e così via. Potrà anche scegliere se scegliere un bucket esistente collegandosi al suo account esistente o se inserire un nome nella riga corrispondente per confermare la creazione di un nuovo bucket.
Concludere il processo di configurazione dello storage S3
Rimangono due possibili opzioni: stato del collegamento al cloud e “upload to the cloud during the job”. Il pulsante Stato del collegamento al cloud le consente di verificare immediatamente la connessione del suo sistema attuale a un cloud di sua scelta. “Upload to the cloud during the job” è un’opzione che viene scelta come parte delle impostazioni predefinite per caricare i dati di backup sul cloud non appena sono pronti (anche durante il processo di un lavoro di backup), ma può anche disattivare questa opzione se desidera caricare dopo la fine di un lavoro o con un altro programma in mente.
Il passo successivo di questa procedura guidata consiste semplicemente nel digitare il nome dell’archivio preferito e la descrizione opzionale.
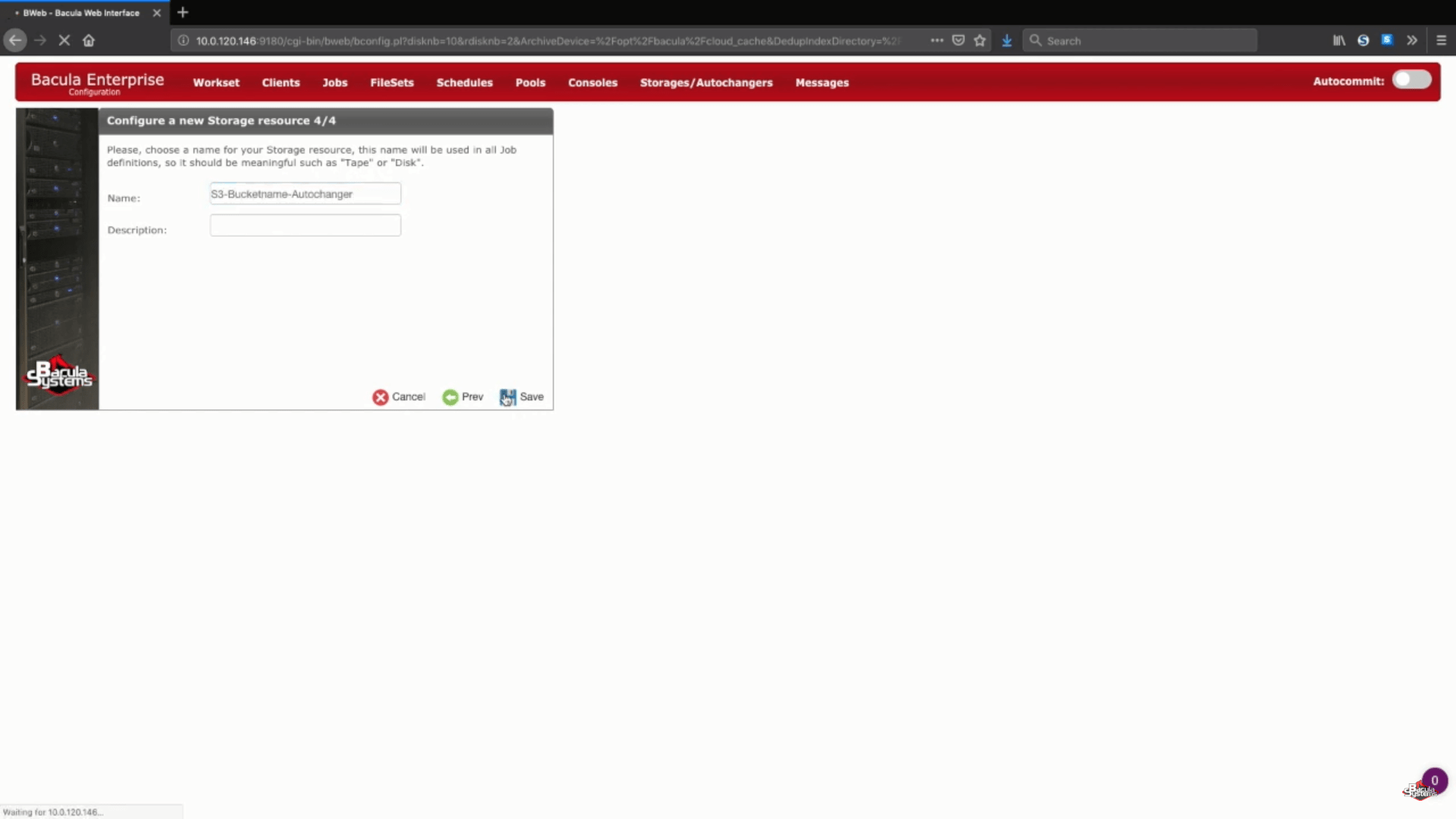
Salvare le nuove impostazioni di backup S3
Dopo questo passaggio, può premere il pulsante “Save” per consentire a tutte le modifiche precedenti di essere impegnate nella produzione. Tenga presente che per impegnare correttamente tutto in produzione, dovrà ricaricare il suo demone di archiviazione, il che significa che qualsiasi lavoro in esecuzione fallirà nel processo.
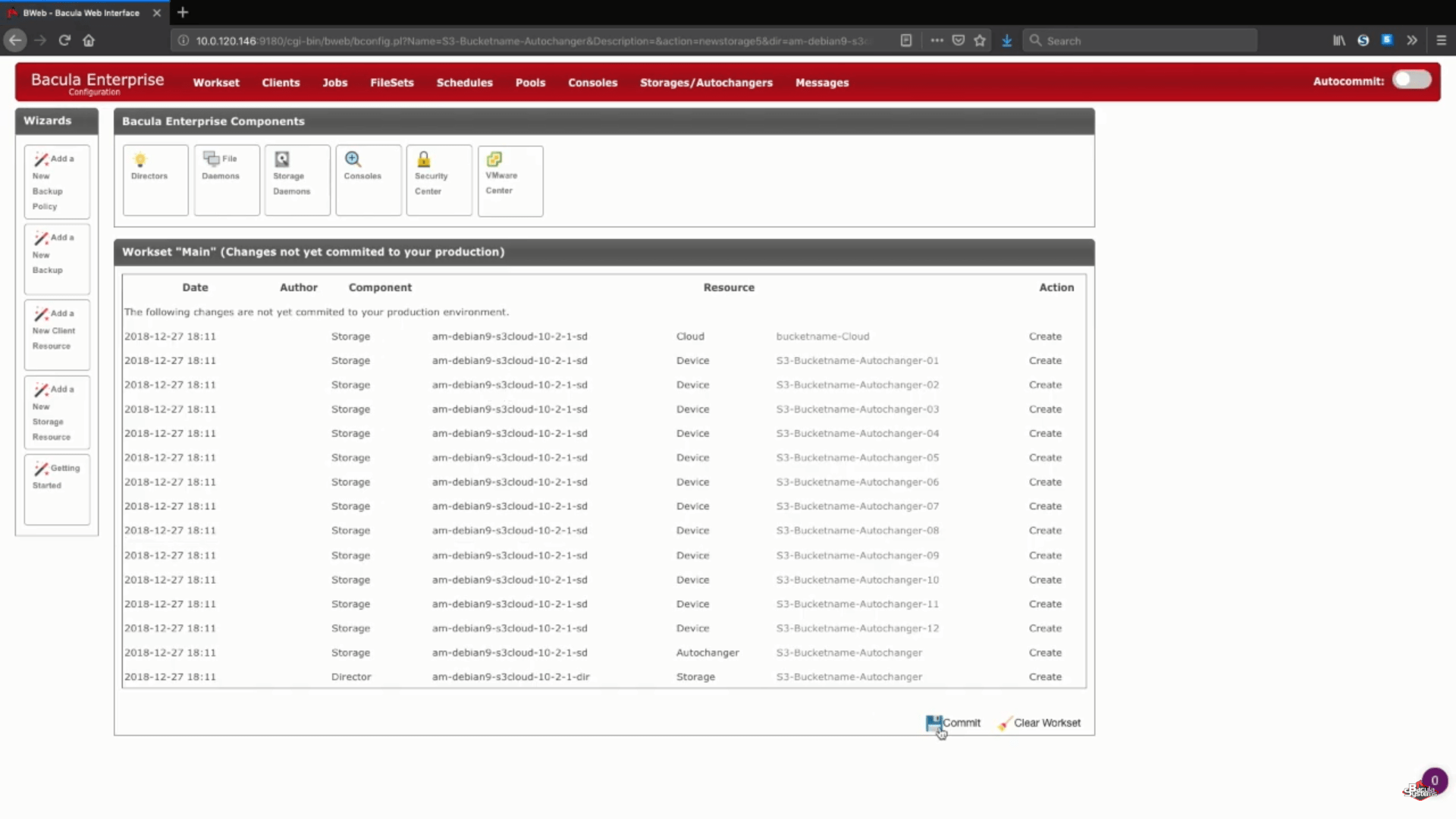
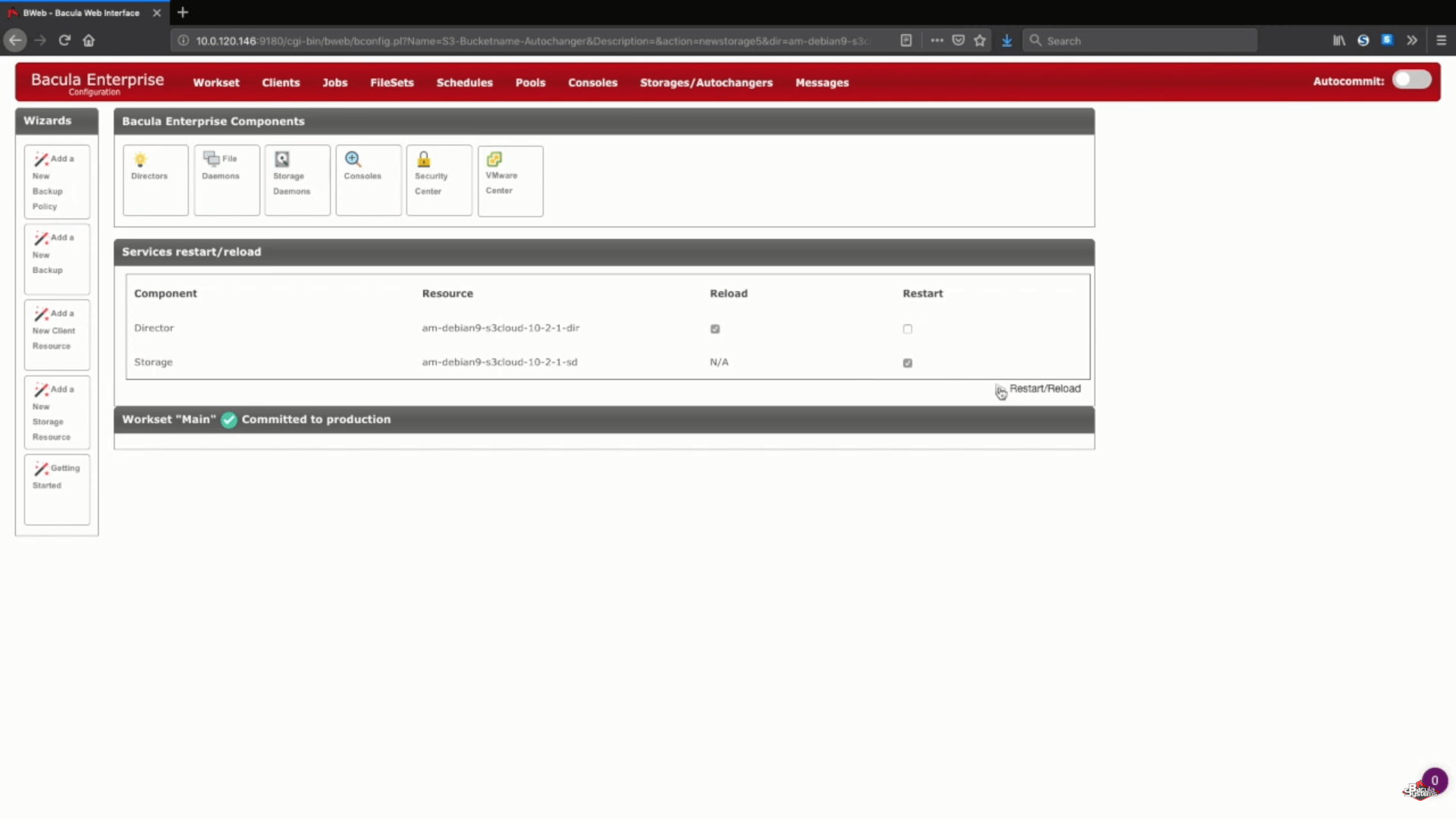
Un passo logico dopo questo sarebbe quello di impostare nuovi pool di backup per questo specifico cloud storage e di configurare correttamente i lavori per scrivere i dati nei nuovi pool. Può consultare la documentazione di Bacula, contattare il nostro supporto o guardare il nostro canale YouTube per ottenere assistenza in merito a questi passaggi.
Test delle impostazioni di backup AWS
Per verificare che tutto ciò che abbiamo appena fatto funzioni correttamente, eseguiremo manualmente un piccolo lavoro di backup Amazon S3 completo direttamente sul nuovo dispositivo di archiviazione. Di solito questo processo viene automatizzato utilizzando un programma di lavoro e/o altre configurazioni.
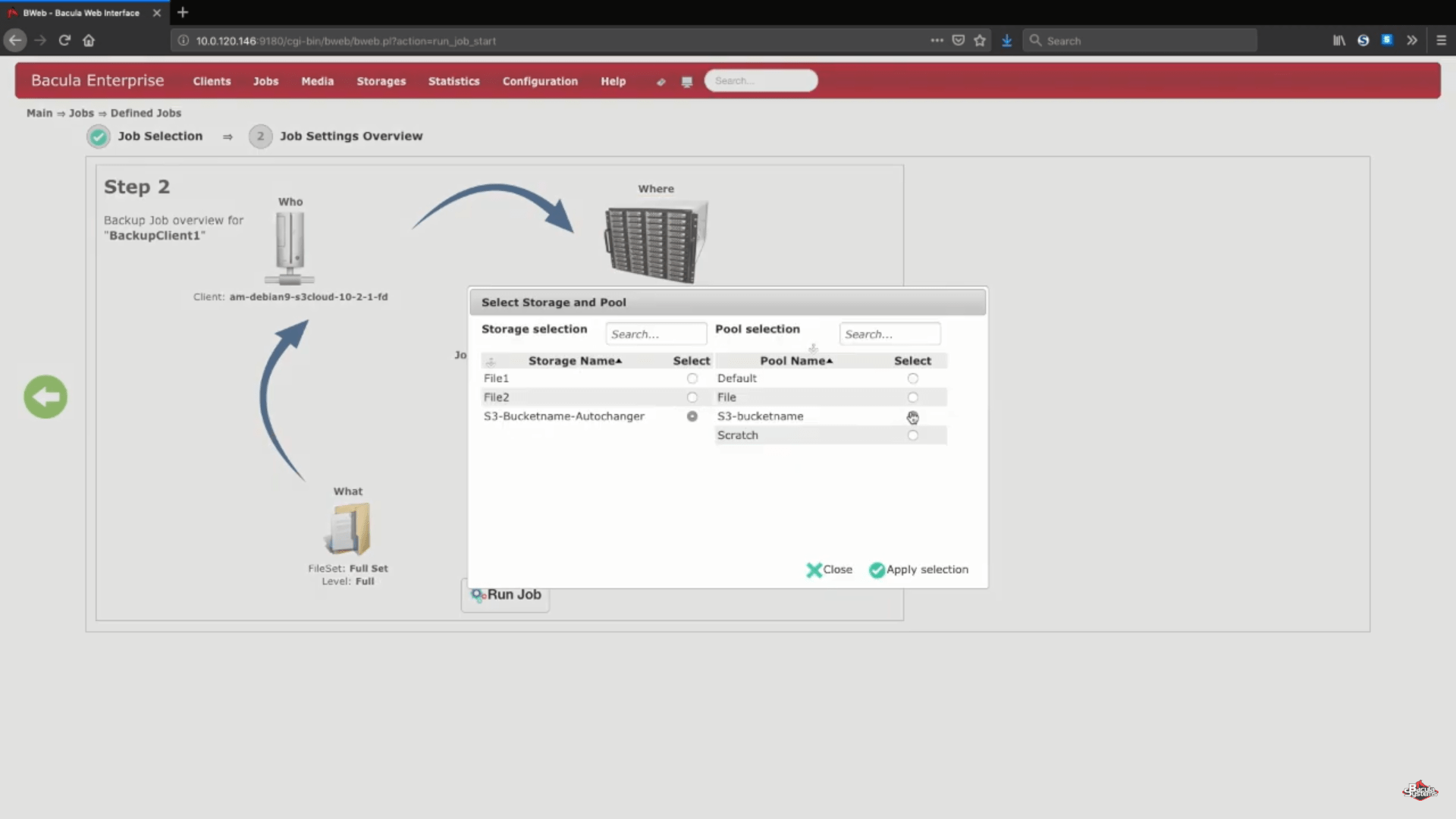
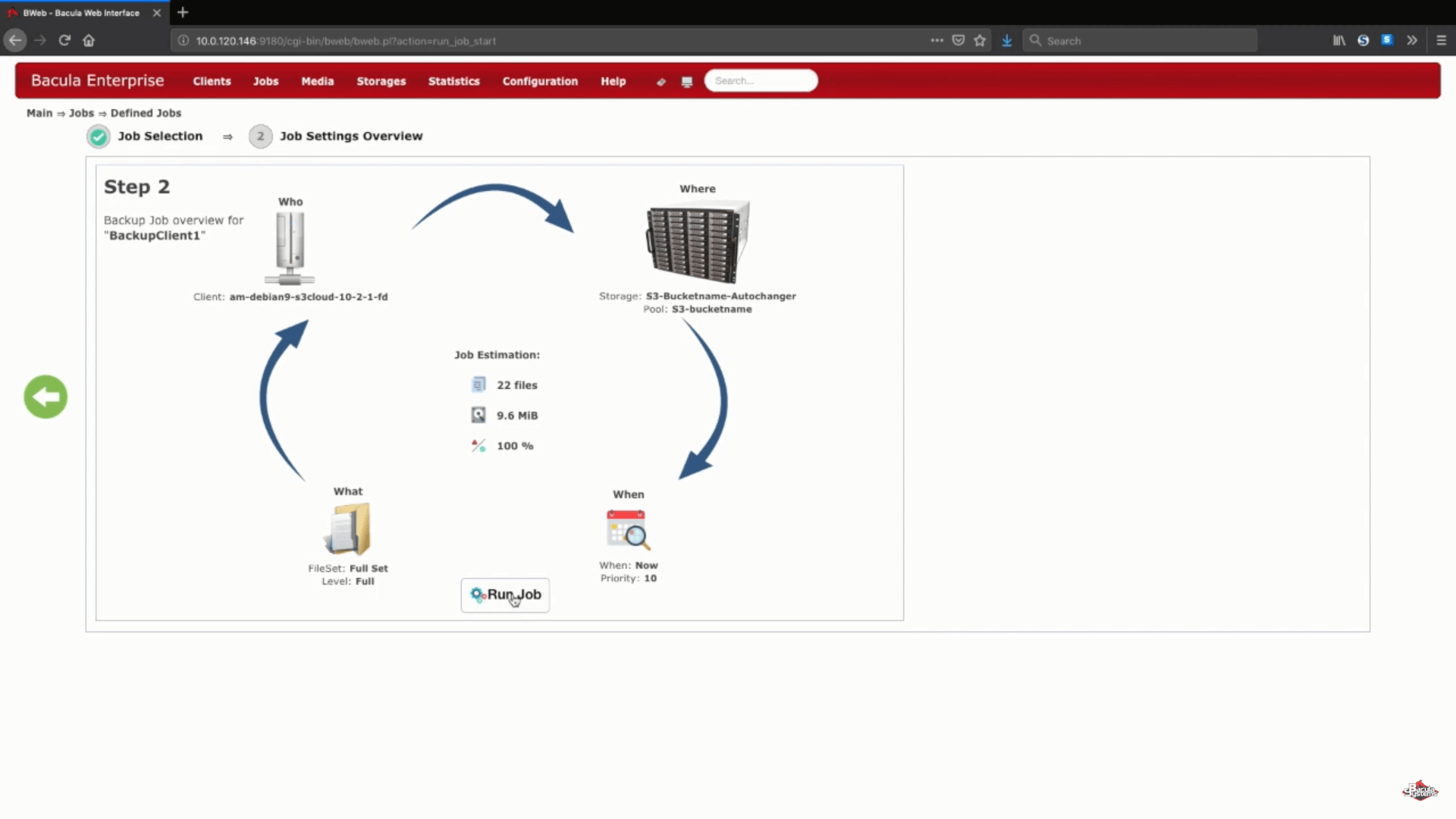
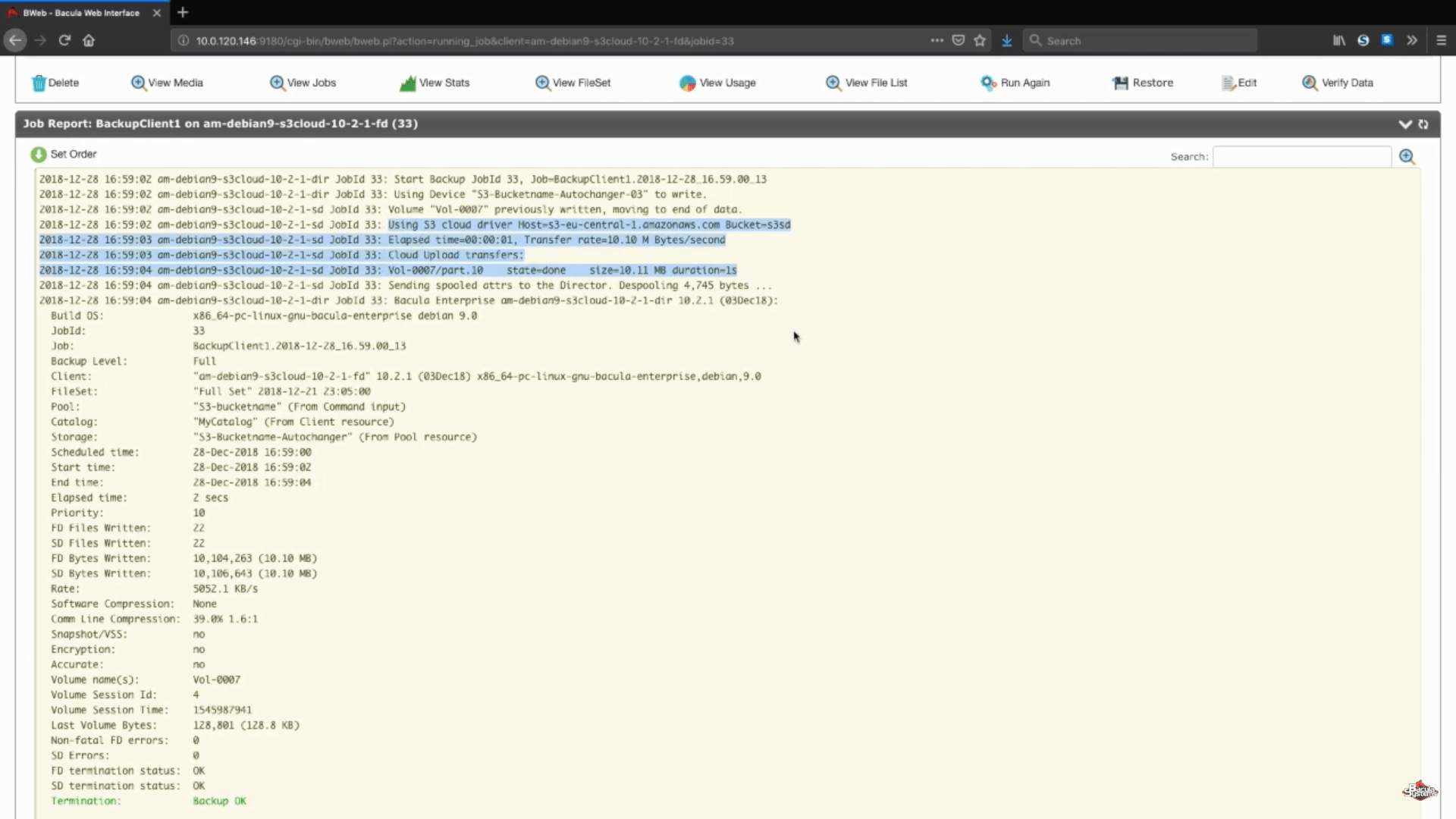
Dopo l’esecuzione del lavoro, potremo vedere i registri dell’intero processo e questa sezione specifica (nello screenshot qui sotto) ci mostra che tutto è stato caricato correttamente.
Conclusione
Bacula Enterprise è una scelta forte per gestire in modo affidabile i suoi backup su AWS S3 e altri cloud, compresa la creazione e la configurazione di nuovi archivi di backup e l’impostazione di lavori di backup da eseguire automaticamente. Dispone inoltre di funzionalità avanzate di configurazione e personalizzazione, combinate con funzioni anti ransomware ultramoderne e aggiornate.

