Enterprise data backup best practices for new Bacula Enterprise users.
- 1. Framework for a Backup Policy
- 1.1 Definition
- 1.2 Example
- 1.3 Notes
- 2. Naming Resources
- 2.1 Naming Resources
- 2.2 Naming Examples
- 2.3 Notes
- 3. Schedules and Retentions
- 3.1 Set up
- 3.2 Schedule and Retention Example
- 3.3 Notes
- 4. Partition Scheme
- 4.1 Requirements
- 4.2 Proposal
- 4.3 Notes
- 5. Disaster Recovery Plan
1. Framework for a Backup Policy
1.1 Definition
A backup policy helps manage users’ expectations and provides specific guidance on the “who, what, when, and how” of the data backup and restore process. Collecting information about backing data up before it is needed helps prevent problems and delays that may be encountered when a user needs data from a backup. There are several benefits to documenting your data backup policy from enterprise data backup best practices point of view:
• It helps clarify the policies, procedures, and responsibilities.
• It will define:
– where backups are located
– who can access backups and how they can be contacted
– how often data should be backed up
– what kind of backups are performed
• Other policies or procedures that may already exist or that supersede the policy (such as contingency plans) are identified.
• A schedule for performing backups is well-defined.
• It will identify who is responsible for performing the backups and their contact information.
This should include more than one person, in case the primary backup operator is unavailable.
• It will define who is responsible for checking that backups have been performed successfully, how and when they will perform this checking.
• A policy ensures data can be completely restored.
• A training plan for those responsible for performing the backups and for the users who may need to access the backups should be mandatory.
• The data Backup is partially, if not fully automated.
• The policy will ensure that more than one copy of the backup exists and that it is not located in same location as the originating data.
• It will ensure that a variety of media are used to backup data, as each media type has its own inherent reliability issues.
• It will ensure that anyone new to the project or office can be given the documentation which will help inform them and provide guidance.
Defining a Data Backup Policy helps overview your infrastructure as well as your backup needs in order to create JobDefinitions, Schedules, Pools and Jobs that will match your environment.
1.2 Example
1. Scope of Policy
2. Purpose
3. Legal and Regulatory Obligations
4. Policy
(a) Schedule of every important piece to be backed up
(b) Storage of the first line Data Backup – Disk
(c) Transport and storage of tapes
(d) Tape Rotation and Storage
(e) Regular data backup verification
(f) Data recovery test in case of disaster recovery – scope and schedule
(g) Restoration request process
(h) Backup logs management
(i) Backup monitoring
(j) Backup Failure Management
(k) Disposal of redundant/damaged tapes
5. Reporting – Role and Responsibilities
(a) Backup and data recovery
(b) Verifications
(c) Disaster Recovery situation
(d) Policy Implementation
(e) Policy Review
1.3 Notes
The information given in this enterprise data backup best practices article is for the purpose of information mainly. It needs to be adapted to the enterprise infrastructure and relevant policy and regulatory obligations of your company.
2. Naming Resources
2.1 Naming Resources
There are a lot of resources you will need to configure in Bacula. Therefore it is
a very good practice to define and standardize the naming. The goal is to avoid
having eg Jobs named Job1,Job2,. . . which do not describe what they do and will
be difficult to trace back after several months of use. Your configuration will gain
clarity.
2.2 Naming Examples
Here are some naming examples for your configuration:
◾ Jobs will have the name of the client, the main function and a trailing -job:
DataServ-MySQL-job
RedHat6-vSphere-job
– Copy/Migration Jobs can have a trailing -copyjob or -migrationjob:
DataServ-MySQL-migrationjob
RedHat6-vSphere-copyjob
– FileSets can be named according to what they do with a trailing -fs
WindowsC-fs
Home-fs
– JobDefs can be named according to the group of clients they for, with atrailing -jd
TestMachines-jd
DedupHomes-jd
DataBase-jd
– Pools can be named according to the location or name of the Storage Daemon, the Media Type, the frequency, the level of the backup and a trailing -pool
NewYorkDailyDedupFull-pool
SafeHouseMonthlyVirtualFull-pool
Bacula-sd2-ZFS-Differential-pool
– Clients could be named with the hostname and a trailing -fd
ceolaptop.domain-fd
– Schedules might contain the frequency and/or the purpose, plus a trailing -sched
DailyEveningVM-sched
– Console should be named with the hostname and a description followed by a trailing -console
VPSalesBackup-console
– Director/Storage Daemon(s)/Clients should be named with their location and hostname. If they are dedicated, one can add a description. At the end we add -dir / -sd / -fd
Iceland-baculabkp-DR-dir
NewYork-storage1-dedup-sd
Houston-clt2314-vsphere-fd
– Autochangers will be easy to find if their name starts with the Storage Daemons name, then a description and a trailing -autochanger
– Devices should refer to the naming of the Storage Daemon they are attached to, as well as, in the case of a Device inside an autochanger, its name and a number. A -device can be added at the end.
NewYork-storage1-dedup-xfs-autochanger-tape2-device
◾ Messages resources can be customized per daemon or per job and a trailing -messages:
ActiveDirectory-SystemState-job-messages
2.3 Notes
◾ Please don’t use spaces in naming, it will work but requires the directives to be quoted.
◾ You can also define acronyms, like DR for Disaster Recovery, EX for External storage or countries such as FR for France.
◾ Use the “Description” directive to add even more details for your resources (when possible).
◾ Stick to your naming convention regarding “-“, “_”, format. Do not rename resources after they were set and used.( See 2.1 on renaming resources for
more details)
◾ Resource names are limited to a fixed number of characters. Currently the limit is defined as 127 characters.
◾ Add comment with a # on directives with values directly in the configuration file ( like File Retention = 94608000 # 3 years in seconds ) to know what it means. For example:
Or use BWeb’s description fields.
3. Schedules and Retentions
Schedules and retentions play a major role in calculating the requirements of a backup system. The number of tapes and the disk space are closely related to these two parameters. For instance, a 10MB backup taken every hour with a retention period of one month would require at least 7200MB of disk space to hold the full backup cycle.
3.1 Set up
Bacula will do exactly what you tell it to do. This is why you should put an extra precaution on your Schedules and Retentions. If the frequency of your Schedule is high and the retentions are long, you will need a lot of disk space. In addition the catalog will be large, as its size is directly proportional to the number of jobs and the retention periods.
On the other hand, if you miss your retention and scheduling, you can have your last Full backup recycled before a new Full has started. The easiest way to deal with schedules and retention is to use a calendar or a spreadsheet to color the days.
3.2 Schedule and Retention Example
Let’s say that we have a pool “Storage1-WeeklyFull-pool” with all retentions set to 7 days. Further we have an incremental pool “Storage1-DailyInc-pool” with the same retention times. The Full backups are scheduled each Monday night and Incrementals daily from Tuesday to Sunday:
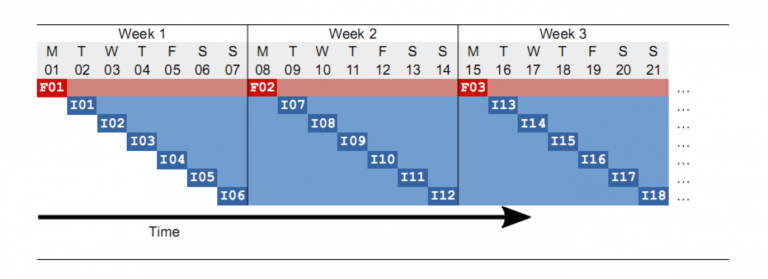
We can see the Full backups in red and the Incremental backups in blue. The retention times are indicated by a lighter color. The first Full F01 will expire on the same day we take the next Full F02. This is dangerous: if for any reason the Full job F02 does not succeed, no Fulls are available at that point in time. In this case, setting the full pool retention to 8 or 9 days allows the backup administrator to run again a Full manually (disabling the Incremental of the day while running) or configure Maximum Full Interval to 7 days to force the promotion of an Incremental to a Full if no Fulls are available in the catalog for the last 7 days.
If you want to guarantee to your users that they can “go back in time” for 7 days, the retention times in the example scheme depicted above will be too short: Imagine a user on day 11 (Thursday) in the morning (I09 will be taken in the late evening) who wants to have a file back from the week before, and the only thing he knows is that he last saw the file on Friday of the previous week. Since the retention time of Full F01 has expired, all the Incremental backup that followed can no longer be used to construct the file tree, because Bacula will need a Full and all following Incremental for this. Thus at this point in time you will only be able to go back to the Monday of the same week when the most recent Full was taken. You are not able to go back 7 days in time. To accomplish this at all times with the above scheme the retention time for the Full should be at least 15 days. Of course it could be that the file we are looking for has changed on day 5 (Friday of the week before) and was backed up in the Incremental I04, but this is a special case. If the file did not change it would not have been in that backup. To cover the general situation and allow to go back in time for 7 days in all scenarios the only way to do it is to choose the retention times that are long enough, according to your backup policies.
3.3 Notes
The example above is a simple one, there are other ways of scheduling: using a specific week number (beware of 53 weeks years), or depending on a specific weekday (4th Sunday for example, beware of months with 5 Sundays). Theses variations must be well verified to avoid overlapping or, worse, missing a Full backup and thus creating a gap. In such a case you would be unable to restore in certain situations. When planning schedules, please pay attention to corner cases, as sometimes the year has 53 weeks and a month, 5 weeks. In such cases if the retention period doesn’t take these situations into account the previous full backup may be pruned before it should. It is recommended to configure Bacula in such a way that two fulls may co-exist for a while. It is better to be safe than sorry.
Along with storage space, the catalog also grows proportionally to the number of files and the frequency of the backups.
Be sure that the Storage Daemon is able to handle the aggregate bandwidth of the backups (the network and the storage speed) and all their checksums (CPU) in order to complete within the backup window.
4. Partition Scheme
4.1 Requirements
Bacula will require some space for temporary files and logs.
By default, the directory /opt/bacula/working is used to store the following things:
◾ BWeb log files
◾ SD attributes
◾ DIR, FD, SD trace and dump files
◾ Plugin log files and other plugin-specific data
It is in the enterprise data backup best practices to have the following partitioning to avoid filling your root space.
4.2 Proposal
◾ at least 10GB+ for /opt, we recommend this value as /opt/bacula/working is heavily used for caching purpose, plugin logs and single file restore mount points and logs.
◾ a separated partition for your catalog (around 150 bytes are used for each files in the catalog).
◾ a separated /opt partition for spooling (if you use spooling to tapes) the size of your spooling (Directive SpoolSize) + 10GB, remember that the spooling of attributes will go by default on /opt/bacula/working, use the Directive Spool Directory to set this spooling partition in your configuration.
4.3 Notes
Bear in mind that partitioning your system will guarantee an efficient load on each partition and avoid fulfilling of the root one
Regarding the space allowed for disk based backup, please configure it to be extensible by using LVM/ZFS or any other mechanism, even by assigning jobs to a dedicated partition and use copy and migration jobs afterwards to keep useful jobs.
5 Disaster Recovery Plan
5.1 Template
Your Disaster Recovery plan should include Bacula’s configuration and backups. In order to do so, you can have off-site backups including your configuration.
The needs are simple, the backups (for example the last fulls of your systems), the content of /opt/bacula/etc and the catalog.
The backups can be copied or migrated using Copy/Migration jobs from one site to a safe site using schedules.
If you are using tapes, you can remove a set of tapes after the Full backups and put them in a safe.
The very important part of this plan is that the catalog and the configuration files are in one single volume.
5.2 Example
This is an example which you need to adapt to your own system.
First, set up a job that will backup /opt/bacula/etc/* and your catalog dump.
We would advise to have all Bacula Enterprise configuration (/opt/bacula/etc/ content) as well as the catalog backup in a dedicated pool to ease the process of recovery as the job will not be mixed in dozen of other jobs. Catalog and configuration files are all you need for recovering
your Bacula backup environment. We will split the backup in 2 parts to insure consistency of the catalog data.
This way we set up a specific pool for our Bacula configuration and catalog backup, 2 jobs per volume. Of course you can tweak this example to have more files backed up to build your own DR plan (eg. TLS keys etc.).
Here is an example of a Pool on hard drives backing up a disaster recovery job
Name = “DisasterRecovery-pool” ActionOnPurge = Truncate AutoPrune = yes
FileRetention = 7 days # Adjust to the schedule of the Disaster Recovery job
# here it is kept 7 days before recycling
JobRetention = 7 days # This is the minimum we want to keep our DR data safe LabelFormat =
“Disaster-”
PoolType = “Backup” Recycle = yes
Storage = “OnDisk”
MaximumVolumeJobs = 2 # Here we want to keep config files and dump on the same
# volume. Adjust here if you don’t want 2 jobs per volume VolumeRetention = 8 days # Do not trust this value to keep your data safe
# this long. You can ask Bacula to do its best VolumeUseDuration = 20 hours # How long do you want your volume available. No more
# than one day (because you will run on DR backup job
# per day, but not too short in case something goes
# wrong during the backup.
# Adjust here depending on your policy Maximum Volumes = 10 # 7 volumes + some spare
}
Here is an example Job and FileSet for a Disaster Recovery plan
Name = “DisasterRecovery-catalog-fs” # FileSet for the Catalog Include {
Options {
Signature = MD5
}
File = /opt/bacula/working/bacula.sql # where the Bacula catalog dump goes
# to be adjusted with your catalog
# dump
}
}
Fileset {
Name = “DisasterRecovery-config-fs” # FileSet for the Bacula Enterprise
# Edition configuration files
Include {
Options {
Signature = MD5
Job {
Name = “DisasterRecovery-catalog-job” Type = “Backup”
Client = “baculaServer” # change to the name of the fd running on the Bacula DIR Fileset =
“DisasterRecovery-catalog-fs”
JobDefs = “Default-jd”
Level = “Full” # full backup is preferable Messages = “Standard”
Pool = “DisasterRecovery-pool” # the pool we just defined to hold all the DR config Priority = 20 #
Adjust this priority to be the highest of the schedule
Runscript {
Command = “/opt/bacula/scripts/make_catalog_backup bacula bacula” RunsOnClient = no
RunsWhen = Before
}
Runscript {
Command = “/opt/bacula/scripts/delete_catalog_backup” RunsOnClient = no
RunsWhen = After
}
Schedule = “NightAfterJobs”
Storage = “OnDisk”
WriteBootstrap = “/opt/bacula/bsr/catalog-backup.bsr”
}
Job {
Name = “DisasterRecovery-config-job” Type = “Backup”
Client = “baculaServer” # change to the name of the fd running on the Bacula DIR Fileset =
“DisasterRecovery-config-fs”
JobDefs = “Default-jd”
Level = “Full” # full backup is preferable Messages = “Standard”
Pool = “DisasterRecovery-pool” # the pool we just defined to hold your DR config Priority = 15
# Adjust if necessary. Must be lower than the catalog’s one Schedule = “NightAfterJobs”
Storage = “OnDisk”
WriteBootstrap = “/opt/bacula/bsr/config-backup.bsr”
}
Here we set different priority for the 2 jobs to ensure that the job that backs up the catalog runs after the backup of the configuration file.
This way, in case of Disaster, you reinstall the same version of Bacula, then you just need to grab the last volume from the DisasterRecovery-pool and use bextract to extract all its content. The 2 jobs will contain the catalog and the config.
You need to re-inject the catalog dump in your database, copy the config files in /opt/bacule/etc/ and everything is back online. (Please test with /opt/bacula/bin/bacula-dir -t -u bacula -g bacula before launching the daemons.)
5.3 Notes
• Please test your Disaster Recovery procedure and document it.
&pt=%2Fenterprise-data-backup-best-practices%2F&ur=https%3A%2F%2Fwww.baculasystems.com%2Fenterprise-data-backup-best-practices&ho=www.baculasystems.com&rf=&ce=true&lg=en-US&ht=720&wd=1280&cd=24&pd=24&ah=720&aw=1280&oa=0&ot=landscape&wh=720&ww=1280&sh=12358&wrh=1&wrw=1&tm=2025-04-26T20%3A27%3A17.789Z)